Стек вызовов
Стек вызовов (от англ. call stack ; применительно к процессорам — просто «стек») — в теории вычислительных систем, LIFO-стек, хранящий информацию для возврата управления из подпрограмм (процедур) в программу (или подпрограмму, при вложенных или рекурсивных вызовах) и/или для возврата в программу из обработчика прерывания (в том числе при переключении задач в многозадачной среде).
При вызове подпрограммы или возникновении прерывания, в стек заносится адрес возврата — адрес в памяти следующей инструкции приостановленной программы и управление передается подпрограмме или подпрограмме-обработчику. При последующем вложенном или рекурсивном вызове, прерывании подпрограммы или обработчика прерывания, в стек заносится очередной адрес возврата и т. д.
При возврате из подпрограммы или обработчика прерывания, адрес возврата снимается со стека и управление передается на следующую инструкцию приостановленной (под-)программы.
Содержание
Реализация
Стек вызовов может быть реализован как в виде специализированного стекового регистра ограниченной глубины (или даже обычного регистра адреса возврата, например в некоторых моделях PowerPC), так и в виде указателя вершины стека в оперативную память или регистровый файл процессора.
При отсутствии или ограниченности стека, вложенные вызовы исключены или их количество ограничено. При необходимости бо́льшей вложенности, стек вызовов или его расширение могут быть реализовано программно.
Поддержка
Вызов подпрограммы и возвраты из подпрограмм и обработчиков прерываний, как правило выполняются специализированными инструкциями процессора. Кроме инструкций вызовов и возвратов, процессоры часто имеют инструкции для использования стека вызовов также и под сохранение данных — их помещения в стек, снятия со стека, модификации содержимого стека.
Инструкции вызова, возврата и работы со стеком могут отличаться по размеру сохраняемых данных (в этом случае необходимо использовать соответствующие друг другу инструкции или их эквиваленты).
Иногда процедуры возврата из подпрограммы и обработчика прерываний отличаются друг от друга, и также требуют разных команд (например, при возврате из прерывания часто необходимо восстановить из стека регистр флагов и/или разрешить обработку конкурентных прерываний, которая может автоматически запрещаться при вызове обработчика).
При отсутствии специализированных инструкций (в процессорах с сокращённым набором команд) вызовы, возвраты и прочая работа со стеком вызовов реализуются обычными инструкциями работы с памятью/регистрами и передачи управления.
Использование
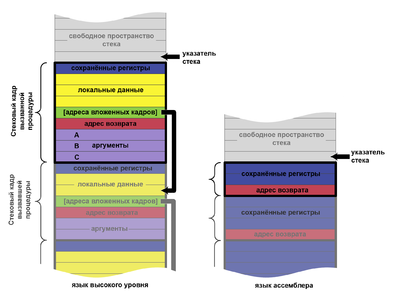

Стек вызовов может использоваться для различных нужд, но основное его назначение — отслеживать место, куда каждая из вызванных процедур должна вернуть управление после своего завершения. Для этого при вызове процедуры (командами вызова) в стек заносится адрес команды, следующей за командой вызова («адрес возврата»). По завершении вызванная процедура должна выполнить команду возврата для перехода по адресу из стека.
Кроме адресов возврата в стеке могут сохраняться другие данные, например:
Использование стека в многозадачных системах
В многозадачных системах, каждая задача как правило имеет свой собственный стек, и при переключении задачи указатель стека процессора переставляется на него.
Нестандартное использование
Стек может быть использован нестандартно, например:
Альтернативное использование
При альтернативном использовании, указатель стека переставляется на область данных и инструкции для работы со стеком используется в качестве строковых операций для обработки последовательных данных в памяти.
При альтернативном использовании обработка прерываний невозможна, т. к. во избежание повреждения данных прерывания должны запрещаться.
Замечания
См. также
Смотреть что такое «Стек вызовов» в других словарях:
Стек — Простое представление стека У этого термина существуют и другие значения, см. Стек (значения). Стек (англ. stack стоп … Википедия
LIFO (информатика) — У этого термина существуют и другие значения, см. LIFO. Самый верхний элемент стека, который добавлен последним, извлекается самым первым. Поэтому такой стек является структурой типа LIFO. LIFO акроним Last In, First Out («последним пришёл первым … Википедия
LIFO — У этого термина существуют и другие значения, см. FIFO и LIFO. Самый верхний элемент стека, который добавлен последним, извлекается самым первым. Поэтому такой стек является структурой типа LIFO LIFO (акроним Last In, First Out, «по … Википедия
ЛИФО — Простое представление стека Стек (англ. stack стопка) структура данных с методом доступа к элементам LIFO (англ. Last In First Out, «последним пришел первым вышел»). Чаще всего принцип работы стека сравнивают со стопкой тарелок: чтобы взять… … Википедия
Проблема фунарга — Фунарг сокращение от «функциональный аргумент»; в компьютерных науках, проблема фунарга относится к сложности реализации функций как первоклассных объектов в стеково ориентированных языках программирования (в широком смысле, включая все… … Википедия
Переполнение буфера — У этого термина существуют и другие значения, см. Переполнение. Переполнение буфера (Buffer Overflow) явление, возникающее, когда компьютерная программа записывает данные за пределами выделенного в памяти буфера. Переполнение буфера обычно… … Википедия
Переполнение стека — Эта статья о компьютерной ошибке. О сайте для программистов см. Stack Overflow. В программном обеспечении переполнение стека (англ. stack overflow) возникает, когда в стеке вызовов хранится больше информации, чем он… … Википедия
Сравнение языков программирования — Эту статью следует викифицировать. Пожалуйста, оформите её согласно правилам оформления статей. Условные обозначения … Википедия
VSTS Profiler — Visual Studio Team System Profiler коммерческий профайлер (иногда употребляют термин «профилировщик») от корпорации Microsoft, входящий в состав пакета Visual Studio Team System (VSTS) и версии Development Edition среды разработки Visual… … Википедия
Visual Studio Team System Profiler — коммерческий профайлер (иногда употребляют термин «профилировщик») от корпорации Microsoft, входящий в состав пакета Visual Studio Team System (VSTS) и версии Development Edition среды разработки Visual Studio[1]. Данный инструмент может работать … Википедия
Вызов функции. Часть 2. Стек и соглашения о вызовах.
Как мы выяснили в части первой, система предоставляет стек каждому потоку. По умолчанию размер стека равен 1 Мб, но он может быть заменен значением, содержащимся в заголовке образа процесса [the process’ image header value]. Размер стека также можно задать при вызове функций CreateThread() или _beginthreadex().
Процессор всегда должен знать, где находится вершина стека. Ее расположение указывает регистр ESP. Значение регистра EIP нельзя изменять явно. Значение регистра ESP не только может быть изменен процессором неявным образом, но также его можно явно изменить с помощью инструкций.
Например:
* Инструкция push неявно уменьшает значение ESP на 4 и кладет 32-битное значение по указанному адресу. Это напоминает добавление карты на вершину колоды. После этого действия стек увеличивается на 4 байта.
* Инструкция pop неявным образом извлекает 32 бита из места, на которое указывает ESP, и затем увеличивает значение ESP на 4. Если использовать аналогию с картами, то она как будто удаляет карту с вершины колоды. Соответственно стек уменьшается на 4 байта.
* Такие инструкции как mov ESP, [source] или sub ESP, [value] уменьшают/увеличивают/изменяют значение ESP явным образом, реально изменяя расположение вершины стека.
Каким образом параметры передаются функции?
Ответ прост: через стек. Код, вызывающий функцию, знает, сколько параметров ей передать и каковы значения этих параметров. Таким образом, если код вызывает функцию sum, которая принимает два параметра типа int, т.е. имеет такую сигнатуру
то вызывающий код делает следующее:
* Он кладет два параметра в стек с помощью двух инструкций push. В результате этого указатель стека (ESP) неявно уменьшается на 2 * 4 байта. Другими словами, вершина стека сдвигается на 8 байт.
* Он вызывает инструкцию call, передавая ей адрес функции sum. При этом значение ESP неявно уменьшается еще на 4 байта, потому что при вызове инструкции call в стек кладется адрес инструкции, к которой возвратится поток после выполнения функции sum (в дальнейшем будем называть его «адрес возврата»).
Каким образом функция получает параметры?
Ответ тоже прост: она извлекает их из стека. Сразу при входе в функцию sum, до выполнения любых инструкций стек выглядит следующим образом: текущее значение ESP (вершина стека) указывает на адрес возврата. Если вы углубитесь в стек на 4 байта (т.е. посмотрите значение, хранящееся в ESP + 4), то там вы найдете один из параметров, переданных функции sum. Пропустите еще 4 байта и по адресу ESP + 8 вы найдете второй параметр функции sum.
Таким образом, при входе в функцию код имеет все, что ему нужно для выполнения.
Соглашения о вызовах [Calling conventions]
__cdecl
__stdcalll
thiscall
В этой части статьи мы подробно рассмотрим механизмы соглашений __cdecl и __stdcall и узнаем, как выглядит стек и скомпилированный код в каждом из этих случаев.
Подробное описание протокола __cdecl можно найти здесь. Особенно важны следующие моменты:
* Порядок передачи аргументов: справа налево
* Ответственность за целостность стека: вызывающая функция должна удалить аргументы из стека
Порядок передачи аргументов в протоколе __cdecl
Порядок передачи аргументов описывает способ, которым аргументы кладутся в стек вызывающим кодом. В случае протокола __cdecl речь идет о порядке «справа налево». То есть последний аргумент кладется в стек в первую очередь, за ним кладется предпоследний аргумент, и так далее, пока все аргументы не окажутся в стеке. Как только это будет сделано, выполняется инструкция call, вызывающая функцию.
Относительно содержимого стека это означает следующее: если вы заглянете в стек, как только попадете в вызываемую функцию, до выполнения каких-либо инструкций внутри нее, то первые 4 байта по адресу, хранящемуся в ESP, будут содержать адрес возврата. Следующие 4 байта (т.е. 4 байта по адресу ESP + 4) будут содержать первый параметр, в четырех байтах по адресу (ESP + 8) будет второй параметр и т.д.
* Запустите Visual Studio 2005. Создайте проект Win32 Console Application и назовите его sum.
* Вызовите окно свойств проекта [Project Properties]. Теперь, чтобы облегчить нашу задачу, нужно отключить настройки, которые заставляют компилятор генерировать некоторый код, что затрудняет понимание сути процесса. В будущем я постараюсь рассмотреть использование этих настроек.
— В окне свойств проекта откройте Configuration Properties->C/C++->Advanced. Здесь в поле Calling Convention установите __cdecl.
— На вкладке Configuration Properties->C/C++->General в поле Debug Information Format выберите Program Database(/Zi).
— На вкладке Configuration Properties->C/C++->Code Generation в поле Basic Runtime Checks установите Default.
— На вкладке Configuration Properties->Linker->General в поле Enable Incremental Linking выберите No.
— Нажмите Ok.
* Измените код, как показано на рисунке ниже, и поставьте точку останова на 13-ую строку (для этого переместите курсор на 13-ую строку и нажмите F9):
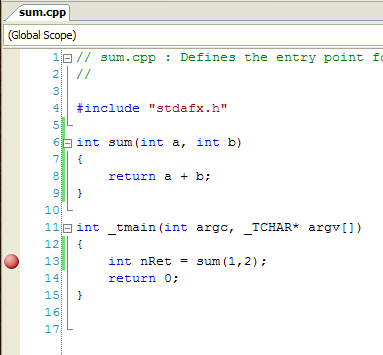
* Соберите проект (пункт меню Build solution).
* Нажмите F5 для запуска программы под отладчиком. Выполнение программы остановится на 13-ой строке.
* Нажмите Alt+5. Появится окно, отображающее содержимое регистров [Registers Window].
* Нажмите Alt+6. Появится окно, отображающее содержимое памяти [Memory Watch Window].
* Перейдите на строку 13, вызовите контекстное меню и выберите Go To Disassembly.
* В дизассемблере снова вызовите контекстное меню и убедитесь, что отмечены следующие пункты:
— Show Address
— Show Source Code
— Show Code Bytes
Окно дизассемблера должно выглядеть следующим образом:
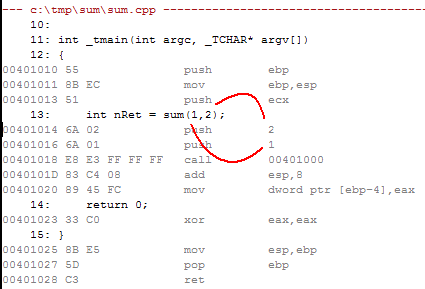
* Обратите внимание на передачу аргументов функции. Поскольку мы используем протокол __cdecl, вы увидите, что параметры действительно кладутся в стек «справа налево». И сразу за ними в стек попадает адрес возврата.
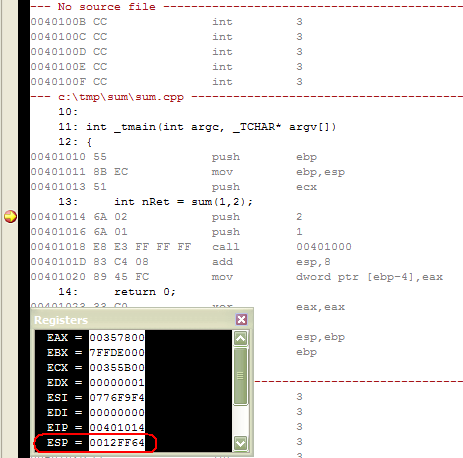
* Запомните значение ESP. Затем выполните первую из инструкций push (другими словами, push 2), нажав F10. Обратите внимание, что значение регистра ESP уменьшилось на 4.
* Снова нажмите F10 и вы увидите, что значение ESP уменьшилось еще на 4.
* Теперь нажмите F11, чтобы войти в вызываемую функцию sum. Окно дизассемблера должно выглядеть так:
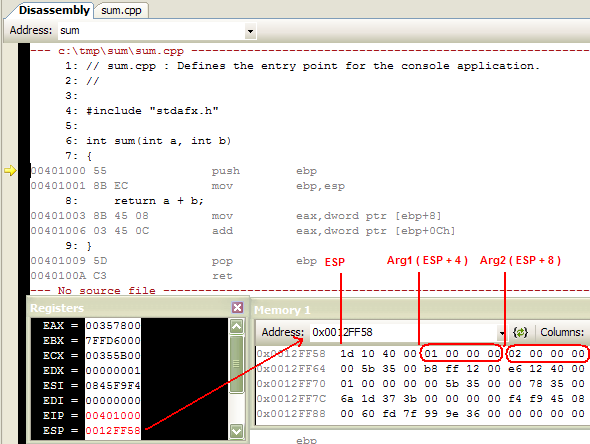
* Если вы теперь наберете ESP в поле Address окна Memory Watch Window, вы увидите, что память по адресу ESP + 4 содержит первый аргумент функции, а по адресу ESP + 8 находится второй аргумент. Другими словами, крайний справа аргумент расположен по наибольшему адресу.
* Нажмите F5, чтобы завершить работу отладчика.
Ответственность за целостность стека в протоколе __cdecl
* Нажмите F5, чтобы запустить программу под отладчиком. Выполнение программы остановится на 13-ой строке.
* Нажмите Alt+5. Появится окно, отображающее содержимое регистров [Registers Window].
* Нажмите Alt+6. Появится окно, отображающее содержимое памяти [Memory Watch Window].
* Перейдите на строку 13, вызовите контекстное меню и выберите Go To Disassembly.
* В дизассемблере снова вызовите контекстное меню и убедитесь, что отмечены следующие пункты:
— Show Address
— Show Source Code
— Show Code Bytes
Окно дизассемблера должно выглядеть следующим образом:
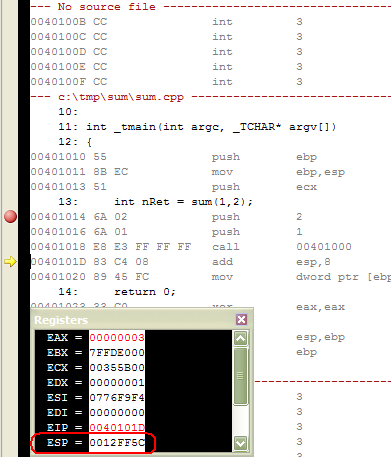
Выводы по протоколу __cdecl
* Ответственность вызывающего кода за целостность стека означает, что если вызывающий код в различных местах вызвал 100 функций, используя протокол __cdecl, то он должен для каждого из этих вызовов выполнить дополнительный код, обеспечивающий целостность стека, даже если вызывалась все время одна и та же функция. Таким образом, объем генерируемого кода может увеличиться.
* Поскольку ответственность за целостность стека лежит на вызывающем коде, протокол __cdecl позволяет создавать список аргументов переменной длины. При вызове функции с переменным числом аргументов только вызывающий код знает, сколько параметров было ей передано. Следовательно, протокол __cdecl очень подходит для такой ситуации.
3.2 Классическая стековая машина
3.2.1 Блок-схема
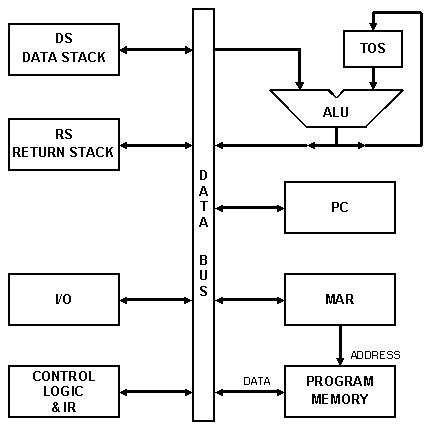
Рис. 3.1 Классическая Стековая Машина
3.2.1.1 Шина данных
3.2.1.2 Стек данных
3.2.1.3 Стек адресов возврата
3.2.1.4 АЛУ и регистр вершины стека
АЛУ поддерживает стандартные элементарные операции, необходимые любому компьютеру. В иллюстративных целях этот набор состоит из сложения, вычитания, логических функций ( «И», «ИЛИ», «ИСКЛЮЧАЮЩЕЕ-ИЛИ» ) и операции проверки на нуль. В соответствии с целями разработки все вычисления идут над целыми числами, но в общем случае нет никаких причин, препятствующих добавлению в АЛУ арифметики с плавающей запятой.
3.2.1.5 Счётчик команд
3.2.1.6 Программная память и регистр адресации памяти
3.2.1.7 Ввод/вывод
3.2.2 Операции над данными
Табл. 3.1 Набор инструкций Классической Стековой Машины
3.2.2.1 Обратная польская запись
Стековые машины проводят действия с данными, используя постфиксные операции. Такие операции обычно называются «обратные польские» по аналогии с «обратной польской записью» ( RPN ), часто используемой для описания постфиксных операций. Их особенностью является то, что операнды идут впереди символа операции. Возьмём, например, выражение в обычной ( инфиксной ) записи:
В этом выражении скобки используются для того, чтобы операция сложения была выполнена перед умножением. В их отсутствие действует подразумеваемое старшинство операций. Например, без скобок умножение будет выполняться перед сложением. В постфиксной записи выражение из примера выше выглядело бы следующим образом:
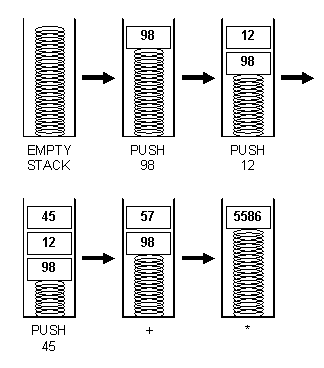
Рис. 3.2 Пример стековой операции
Выражения в постфиксной записи получаются компактнее, по сравнению с инфиксной, так как не требуют ни правил старшинства операторов, ни скобок. Они гораздо лучше подходят под нужды компьютеров. На самом деле, компиляторы, естественно, переводят инфиксные выражения, написанные на языке подобном Си или FORTRAN, в постфиксные машинные коды, иногда используя явное распределение регистров вместо стека для вычисления выражений.
«Классическая Стековая Машина» спроектирована так, чтобы выполнять постфиксные операции непосредственно, не обременяя компилятор регистровой бухгалтерией.
3.2.2.2 Арифметические и логические операторы
В соответствии с требованиями по обеспечению базовых вычислений «Классической Стековой Машине» нужны арифметические и логические операторы. В этом и последующих разделах передача данных между регистрами для каждой инструкции будет поясняться псевдокодом. Например, первая операция «сложение».
| Операция: | + |
| Стек: | N1 N2 → N3 |
| Описание: | Складывает N1 и N2 и возвращает сумму N3 |
| Псевдокод: |
| Операция: | — |
| Стек: | N1 N2 → N3 |
| Описание: | Вычитает N2 из N1 и возвращает разность N3 |
| Псевдокод: |
| Операция: | AND |
| Стек: | N1 N2 → N3 |
| Описание: | Выполняет побитное логическое умножение N1 и N2 и возвращает результат N3 |
| Псевдокод: |
| Операция: | OR |
| Стек: | N1 N2 → N3 |
| Описание: | Выполняет побитное логическое сложение N1 и N2 и возвращает результат N3 |
| Псевдокод: |
| Операция: | XOR |
| Стек: | N1 N2 → N3 |
| Описание: | Выполняет «сложение по модулю 2» N1 и N2 и возвращает результат N3 |
| Псевдокод: |
Очевидно, что буферный регистр верхнего элемента стека экономит заметный объём работы при выполнении этих операций.
3.2.2.3 Операторы для работы со стеком
Одна из проблем машин классической стековой архитектуры состоит в том, что они могут проводить арифметические операции только с двумя верхними элементами стека. Таким образом, на подготовку операндов для вычисления приходится тратить дополнительные инструкции. Следует, естественно, отметить, что некоторые регистровые машины тоже тратят много дополнительных инструкций, перемещая данные между регистрами в процессе подготовки к вычислениям и, таким образом, вопрос о том какой подход лучше становится чуть более запутанным.
Нижеследующие инструкции предназначены для работы с элементами стека.
| Операция: | DROP |
| Стек: | N1 → |
| Описание: | Удаляет N1 из стека |
| Псевдокод: |
Здесь и далее в описаниях инструкций используется запись, подобная «TOSREG ← POP(DS)». В ходе выполнения этой операции данные из стека выставляются на шину данных, затем проходят через АЛУ, где над ними совершается какая-либо пустая операция ( например, сложение с нулём ), чтобы результат положить в регистр вершины стека.
| Операция: | DUP |
| Стек: | N1 → N1 N1 |
| Описание: | Делает копию N1 и помещает её в стек |
| Псевдокод: |
| Операция: | OVER |
| Стек: | N1 N2 → N1 N2 N1 |
| Описание: | Делает копию второго сверху элемента стека N1 и помещает её в стек |
| Псевдокод: |
| Операция: | SWAP |
| Стек: | N1 N2 → N2 N1 |
| Описание: | Меняет местами два верхних элемента стека |
| Псевдокод: |
| Операция: | >R ( Читается как «to R» ) |
| Стек: | N1 → |
| Описание: | Кладёт N1 в стек возврата |
| Псевдокод: |
Инструкция «>R» и её дополнение «R>» позволяет перемещать элементы данных между стеками данных и адресов возврата. Эти команды используются для временного перемещения верхних элементов в стек возврата для получения доступа к данным, лежащим глубже двух первых уровней стека.
| Операция: | R> ( Читается как «R from» ) |
| Стек: | → N1 |
| Описание: | Извлекает верхний элемент из стека возврата и кладёт его в качестве N1 в стек данных |
| Псевдокод: |
3.2.2.4 Чтение и запись памяти
Если все арифметические и логические операции проводятся только над элементами стека, то должен существовать способ загрузки в стек данных или выгрузки данных из стека для сохранения в памяти. «Классическая Стековая Машина» использует простую архитектуру вида «загрузить/сохранить» и поэтому использует одну инструкцию загрузки «@» и одну инструкцию сохранения «!».
У инструкций отсутствует поле операнда, а адрес памяти берётся из стека, что облегчает доступ к членам структуры данных, так как указатель в стеке можно индексировать поэлементно. Инструкции требуют двух циклов обращения к памяти: один для команды и один для данных.
| Операция: | ! ( Читается как «store» ) |
| Стек: | N1 ADDR → |
| Описание: | Сохраняет N1 по адресу ADDR в программной памяти |
| Псевдокод: |
| Операция: | @ ( Читается как «fetch» ) |
| Стек: | ADDR → N1 |
| Описание: | Считывает значение из программной памяти по адресу ADDR и возвращает его в N1 |
| Псевдокод: |
3.2.2.5 Символьные константы
| Операция: | [LIT] |
| Стек: | → N1 |
| Описание: | Рассматривает следующее программное слова как целое число и сохраняет его в стеке в качестве N1 |
| Псевдокод: |
Такая реализация предполагает, что PC указывает на адрес памяти, следующий после кода операции.
3.2.3 Выполнение инструкций
До настоящего момента механизм выборки команд из памяти не учитывался. Обычно под ним подразумевается стандартная последовательность из выборки, декодирования и исполнения инструкции.
3.2.3.1 Счётчик команд
Внутренняя последовательность действий, выполняемая при обработке каждой команды, выглядит так:
| Операция: | [Fetch next instruction] |
| Стек: | |
| Описание: | Выбирает следующую инструкцию |
| Псевдокод: |
3.2.3.2 Условные переходы
| Операция: | [IF] |
| Стек: | N1 → |
| Описание: | В том случае, когда значение N1 ложно ( равно нулю ) в PC загружается адрес из следующего программного слова, в противном случае в PC загружается адрес очередной команды |
| Псевдокод: |
3.2.3.3 Вызов подпрограмм
И, наконец, «Классическая Стековая Машина» должна иметь возможность вызова подпрограмм. Наличие специального стека, выделенного под адреса возврата, позволяет вызывать подпрограммы, просто сохраняя в стеке текущее состояние счётчика команд и загружая в него новое значение. Мы будем считать, что формат инструкции вызова подпрограммы позволяет указать полный адрес процедуры в одном машинном слове, и опустим реальный механизм извлечения из него поля адреса. Реальные процессоры, рассматриваемые в последующих частях книги, предлагают различные способы решения этой задачи при весьма умеренных аппаратных затратах.
Возврат из подпрограммы выполняется простым выталкиванием с вершины стека адреса возврата и помещения его в счётчик команд. Из-за того, что данные хранятся в отдельном стеке, никаких дополнительных действий с указателями или памятью при вызове подпрограмм не требуется.
| Операция: | [CALL] |
| Стек: | |
| Описание: | Выполняет вызов подпрограммы по адресу, расположенному в следующем программном слове |
| Псевдокод: |
| Операция: | [EXIT] |
| Стек: | |
| Описание: | Выполняет возврат из подпрограммы |
| Псевдокод: |
3.2.3.4 Постоянные и подгружаемые наборы инструкций
Для сохранения простоты, описание «Классической Стековой Машины» свободно от рекомендаций по разработке, но, всё же, следует рассмотреть основные сложности, возникающие при воплощении реальных конструкций. Одним из вопросов является выбор между постоянным и подгружаемым набором инструкций. Введение в технику реализации постоянных и подгружаемых наборов можно найти в Koopman ( 1987a ).
Конструкции с постоянным набором обычно быстрее и компактнее. Ценой повышения производительности является бОльшая сложность схемы декодирования и серьёзный риск полной переделки управляющей логики при изменении требований к набору команд ближе к концу срока разработки.
Дополнительным плюсом является тот факт, что в 16— и более разрядных машинах ширина слова заметно больше, чем несколько бит, необходимых для кодирования всех возможных операций. С учётом этого факта модели с постоянным набором используют частично декодированный формат инструкций, позволяющий упростить аппаратуру и увеличить её гибкость. Частично декодированные ( они же не полностью кодированные или «раскодированные» ) инструкции имеют формат, похожий на микрокод, в котором отдельные поля команды отведены под определённые задачи. Это позволяет комбинировать в одном машинном слове несколько независимых операций ( таких, как «DUP» и «[EXIT]» ).
Все эти преимущества жёсткого декодирования могут создать впечатление о бесперспективности применения подгружаемых наборов команд. Тем не менее, у микрокода есть некоторые полезные свойства.
Одним из изъянов микрокода является то, что часто в попытке избежать снижения скорости при обращении к памяти микрокодов приходится использовать конвейер выборки микроинструкций. Это может привести к необходимости увеличения времени исполнения инструкции до двух тактов и более, в то время как конструкции и постоянным набором оптимизированы на исполнение за один такт.
С практической точки зрения, микрокод обычно реализуют в разработках на дискретной логике, поэтому они доминируют в одноплатных решениях. Большинство однокристальных моделей имеет постоянный набор команд.
3.2.4 Изменение состояния
Для приложений реального времени очень важен способ обработки процессором прерываний и переключения задач. Набор команд «Классической Стековой Машины» обходит этот проблему, поэтому мы поговорим о стандартных путях решения, чтобы иметь в дальнейшем основу для сравнения конструкций.
3.2.4.1 Прерывания по переполнению и антипереполнению стека
Прерывания вызываются как исключительными событиями, например, переполнением стека, так и запросами на обслуживание ввода/вывода. Оба вида событий требуют быстрой реакции, не нарушающей логику работы текущего процесса.
Прерывания по переполнению/антипереполнению стека на данный момент самые частые исключительные ситуации в стековых машинах, и поэтому именно на них будет показано, как происходит обработка подобных событий.
Упомянутые исключения возникают в момент исчерпания всего объёма аппаратной стековой памяти. Реагировать можно по-разному: не предпринимать никаких действий и позволить программе завершиться аварийно ( самое простое в реализации, но и самое бесполезное решение [*] ), остановить программу с сообщением о фатальной ошибке и, наконец, переместить часть содержимого стека в системную память, чтобы продолжить исполнение. Понятно, что последний вариант даёт больше всего возможностей, но остановка по ошибке проще в исполнении и в некоторых случаях может быть допустима.
Кроме того, так же могут обрабатываться и другие исключения, например, ошибка чётности памяти.
Исключительные ситуации могут требовать для своей обработки много времени, но в ходе разрешения все они должны сохранять состояние прерванной задачи неизменным, чтобы её исполнение можно было восстановить, если это возможно. Таким образом, исключения не должны требовать от процессора иных действий, кроме аппаратного вызова подпрограммы-обработчика.
3.2.4.2 Прерывания от подсистемы ввода/вывода
Обслуживание ввода/вывода достаточно частое событие, требующее быстрой обработки в системах реального времени. К счастью, такие прерывания обычно требуют немного вычислительных ресурсов и почти не требуют памяти. По этим соображениям в стековых архитектурах прерывания рассматриваются как аппаратно сформированные вызовы подпрограмм.
Такие вызовы кладут параметры в стек, проводят необходимые вычисления, после чего возвращают управление прерванной программе. Есть только одно требование: программа-обработчик прерывания не должна оставлять после себя «мусор» в стеке.
Накладные расходы на обработку прерываний в стековых машинах много ниже, чем в обычных архитектурах. Тому есть несколько причин. Нет нужды сохранять регистры, так как рабочее место в стеке заводится по мере надобности. Нет флагов состояния, требующих сохранения, так как для ветвления программ используются содержимое стека данных. Наконец, конвейер данных в большинстве стековых процессоров или отсутствует вовсе, или очень короткий, и штраф при сохранении его состояния при входе в прерывание отсутствует.
3.2.4.3 Переключение задач
Переключение задач происходит, когда процессор заменяет одну программу на другую, чтобы создать видимость одновременного их исполнения. Состояние программы, останавливаемой при переключении, должно быть сохранено, чтобы она могла продолжить работу позднее. Состояние программы, активируемой в ходе переключения, должно быть полностью восстановлено до момента возобновления её работы.
Общепринятым способом достижения этой цели является использование таймера и переключение задач при каждом его отсчёте с возможным использованием алгоритмов приоритезации и планировки. В простых процессорах это может привести к заметному увеличению накладных расходов на сохранение и восстановление обоих стеков в памяти при каждом переключении контекста. В качестве решения проблемы можно предложить программную технику, использующую «легковесные» задачи, которые не требуют много места в стеке. Такие задачи могут класть свои параметры в стек поверх имеющегося содержимого и освобождать занятое место по завершении, исключая тем самым более дорогостоящее сохранение и восстановление стекового контекста более «тяжёлых» задач.
Другим решением может быть несколько наборов указателей стеков для нескольких задач, использующих общий блок стековой памяти.



