Как научить компьютер узнавать знакомых и незнакомых
У каждого человека есть свои вокальные характеристики — темп, громкость и интонация голоса,— обусловленные индивидуальной структурой его голосового аппарата. Прислушиваясь к разговору, человек может на уровне подсознания идентифицировать голоса. Но можно ли научить этому компьютер?
При разработке алгоритма идентификации личности по голосу решаются две подзадачи: распознавание говорящего и проверка. Распознавая говорящего человека, компьютер сравнивает образец речи с шаблоном из базы данных и ищет соответствия.
Сами системы распознавания могут быть разделены на текстозависимые и текстонезависимые: известен ли системе текст, который должен быть произнесен пользователем, и использует ли система данную информацию. При текстозависимом распознавании могут использоваться как фиксированные фразы, так и фразы, сгенерированные системой и предложенные пользователю. Текстонезависимые системы предназначены обрабатывать произвольную речь.
Сейчас используются несколько алгоритмов создания таких систем.
Например, алгоритм динамического преобразования времени (Dynamic Time Warping) используется для текстозависимых систем. Этот алгоритм используется для распознавания речи в том случае, когда два разных человека произнесли какую-либо одну фразу и надо узнать, кто именно. Для этого компьютер сравнивает две «карты» голоса, отображенные на синусоидных графиках (рис. 1, а). Для сравнения достаточно всего два-три слова.
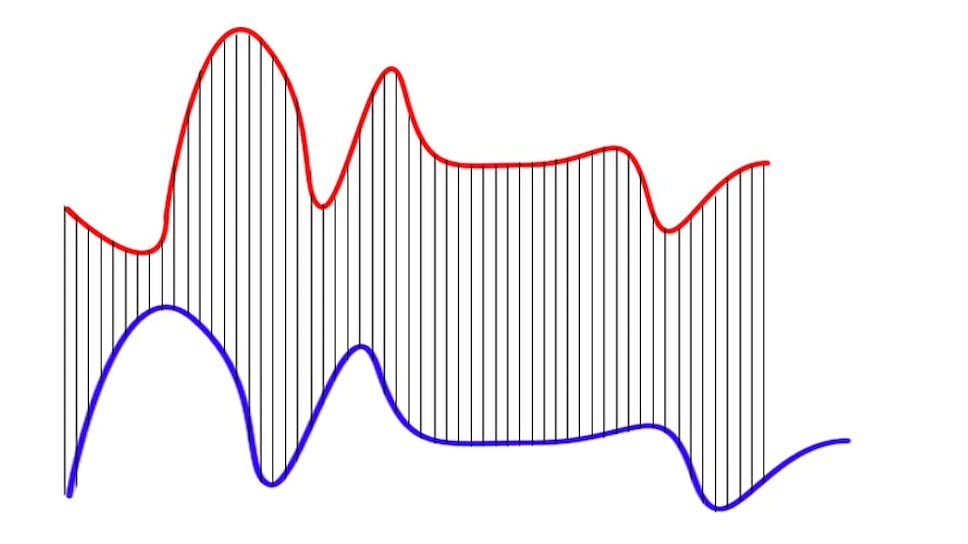
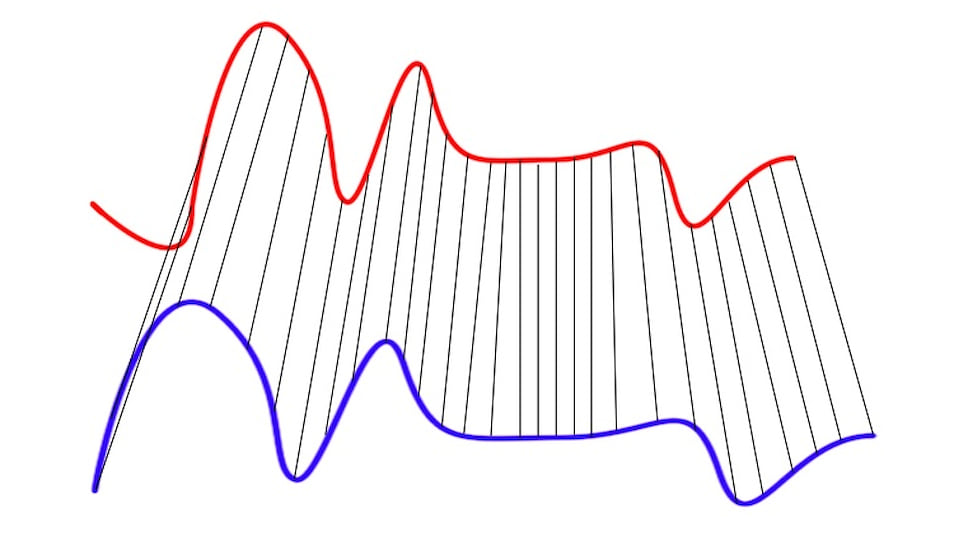
Но бывает так, что эти графики у людей очень похожи. Чтобы сравнить такие голоса, компьютер будет «деформировать» ось времени одного или обоих графиков, чтобы достигнуть лучшего выравнивания (рис. 1, б). Ошибки возникают из-за того, что сравниваемые последовательности имеют разную длину и точка одного ряда будет расположена немного выше или немного ниже соответствующей точки в другом ряду. Поэтому алгоритму трудно найти видимое выравнивание двух строк. Тем не менее он хорошо справляется с распознаванием отдельных слов в ограниченном словаре. Это простой и открытый для улучшения алгоритм, подходящий для приложений в телефонах, автомобильных компьютерах или системах безопасности.
Другой алгоритм — метод опорных векторов, или SVM (от англ. Support Vector Machines), удобно применять, когда требуется идентифицировать каждого человека в большой группе говорящих людей. Этот алгоритм создает линию или гиперплоскость, которая делит данные на классы. Как в детской задаче, где надо одной линией разделить красные и синие кружочки, алгоритм должен найти наиболее правильную линию (рис. 2). Но таких линий может быть очень много. Как же алгоритм находит «ту самую»? Компьютер ищет такие точки на графике, которые расположены ближе всего к линии разделения. Эти точки называются опорными векторами. Затем алгоритм вычисляет расстояние между опорными векторами и разделяющей плоскостью. Основная цель алгоритма — найти такое место, где это расстояние будет максимально большим. Алгоритм может работать и с трехмерной моделью.
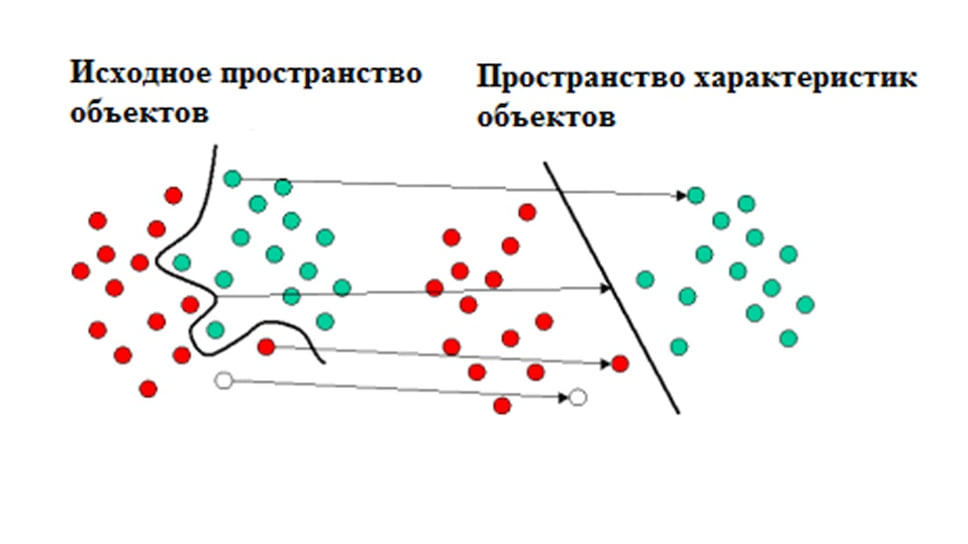
Это позволяет использовать его в анализе и классификации больших объемов данных или разрозненных данных из разных источников. Алгоритм может быть использован для выявления закономерностей в данных и создания структуры, которая потом используется для классификации. Для этого нужно ввести набор входных данных и соответствующих им выходных данных, которые используются для анализа и извлечения паттерна. При этом нам не нужно понимать поведение данных, алгоритм сам будет наблюдать за данными и связями внутри них. Кроме того, этот алгоритм хорошо умеет фильтровать шумы и ошибки данных, что часто нужно при распознавании голоса.
Оба этих алгоритма используются в современных устройствах — телефонах, роботах, системе «умный дом», компьютерах и автомобилях. И алгоритм динамического преобразования временной шкалы, и метод опорных векторов могут помочь организовать регламентированный доступ пользователей по заданной парольной фразе к ресурсам предприятия, телефонным и интернет-сервисам. Эти технологии могут упростить процесс идентификации пользователя без ущерба для информационной безопасности устройства.
Системы могут и будут улучшаться. Сегодня ученые пробуют дополнить алгоритмы языковыми моделями, которые будут описывать структуру языка — например, последовательность слов. Применение нейронных связей — это еще один этап. При этом каждое новое распознавание будет улучшать каждое новое распознавание в будущем. Таким образом, система станет самообучаемой.
Яндекс научил Алису узнавать владельца по голосу

Голосовой помощник «Алиса» научился распознавать владельца по голосу. Для этого пользователю необходимо повторить за помощником пять фраз, чтобы алгоритм смог составить модель голоса. Пока что это позволяет «Алисе» учитывать музыкальные предпочтения только одного пользователя, сообщается на сайте Яндекса.
Современные голосовые помощники умеют не только рассказывать о погоде или отвечать на поисковые запросы, но и выполнять более важные функции. Например, они могут зачитывать мероприятия из календаря или последние личные сообщения, а также активировать подключенные устройства, такие как кондиционер или лампа. Это потенциально способно облегчить жизнь пользователей, но также представляет собой опасность, потому что доступ к такому инструменту могут получить посторонние люди.
Для защиты от неправомерного доступа многие популярные голосовые помощники, такие как Google Assistant, Siri и Alexa, оснащены функцией распознавания голоса. Теперь эту функцию получил и голосовой помощник «Алиса» от Яндекса. Для настройки функции умной колонке необходимо сказать «Алиса, запомни мой голос». После этого помощник сначала спрашивает имя пользователя, а затем просит его повторить пять фраз, на основе которых алгоритмы создают модель голоса для последующего распознавания.
Пока функция распознавания голоса в «Алисе» имеет несколько ограничений. Во-первых, она работает только с музыкой и позволяет не учитывать в будущем музыкальные предпочтения других людей, когда они просят колонку поставить те или иные песни или жанры. Во-вторых, сервис умеет запоминать только одного пользователя. В-третьих, если у пользователя есть несколько колонок разных моделей, процедуру запоминания голоса необходимо пройти на каждой из них. Кроме того, оказалось, что попросить Алису забыть голос может любой пользователь, даже если голосовой помощник запомнил не его.
Установление принадлежности записанного голоса и звучащей речи конкретному лицу (идентификация говорящего)
Установление принадлежности записанного голоса и звучащей речи конкретному лицу (идентификация говорящего) – это одна из разновидностей фоноскопической экспертизы, которая, в свою очередь, представляет собой комплекс исследований относительно голоса и звучащей речи. С помощью данного вида исследования можно определить, чей голос звучит на аудиозаписи. Кроме основного параметра (звучащего голоса/голосов), данный вид исследования позволяет установить разнообразные дополнительные характеристики записи, а именно: возможности применения к анализируемому материалу копирования, монтажа, стирания.
Экспертизы по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) можно разделить на две группы: идентификационные и диагностические. К первой можно отнести вопросы, связанные с идентификацией личности, источников звука и средств видео- и звукозаписи. Ко второй относятся вопросы, связанные с установлением особенностей личности, материалов и средств звукозаписи. Активное распространение экспертизы по установлению принадлежности записанного голоса и звучащей речи конкретному лицу связано с развитием технологической сферы, которая привела не только к совершенствованию аппаратуры для аудиозаписи, но и созданию новых средств и программ для анализа речи и голоса. Данные средства позволили сделать экспертный процесс объективным, во много раз повысить его результативность, повысить сложность исследования.
Предметом фоноскопической экспертизы при установлении принадлежности записанного голоса и звучащей речи конкретному лицу является аудиозапись на магнитном или цифровом носителе одного или нескольких разговоров, полученных в ходе проведения оперативно-розыскных мероприятий, действий, проводимых в ходе судебных разбирательств. Экспертиза аудиозаписи проводится, как правило, чтобы помочь суду, следствию установить подлинность и достоверность фонограммы. Однако исследование проводится также и без согласования с судом по инициативе лица, которое предоставило фонограмму.
Фоноскопическая экспертиза по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) предоставляет широкий спектр возможностей:
Кто проводит экспертизу по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего)?
Проведение экспертизы аудиозаписи относится к числу трудоемких видов исследования, требующих специальных знаний. Сложность работы эксперта в ходе экспертизы по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) состоит в том, что специалист должен разбираться во множестве нюансов, ведь речь человека уникальна: на этой отличительной особенности построены принципы экспертизы аудиозаписи. Голос человека индивидуален и в разное время суток имеет различное звучание. Также звучание голоса зависит от физического состояния человека (усталость, болезнь), психологической и акустической обстановки. Однако преднамеренно подделать голос невозможно. Специалисты в области экспертизы аудиозаписи должны обладать широчайшим спектром знаний в области разных наук: физики, техники, психологии, медицины, лингвистики, психологии.
Экспертиза по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего), как правило, проводится двумя экспертами: инженером и лингвистом. Первый работает с физическими голосовыми характеристиками (высота, частота, длительность звука), выявляя технические параметры аппаратуры и аудиозаписи. Эксперт-лингвист оценивает лингвистические, социальные и психофизиологические составляющие. Необходимо отметить, что экспертное исследование несколько отличается от научного, в строгом смысле слова, и не призвано демонстрировать уровень знаний специалиста или новую информацию об объекте исследования. Цель экспертизы аудиозаписи заключается в другом: применить знания для описания предмета исследования, установления истины в соответствии с поставленным вопросом.
Что необходимо предоставить на экспертизу по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего)?
Для экспертизы необходимо предоставить следующие сравнительные образцы:
Также для проведения экспертизы по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) образец аудиозаписи должен отвечать следующим параметрам:
Является ли аудиозапись доказательством, которое можно представить в суд?
В последнее время бытует мнение, что аудиозапись не является доказательством и не принимается следственными и судебными органами. Это заблуждение, так как законодательно представлять аудиозапись в качестве доказательства разрешено, о чем свидетельствуют статьи 59 и 60 Гражданского процессуального кодекса, 67 и 68 Арбитражного процессуального кодекса. Эти статьи говорят о возможности предоставления аудиозаписи в качестве доказательства, но только после подтверждения ее относимости, допустимости и достоверности. Необходимо также указать условия проведения записи, кем и когда была сделана фонограмма. Данное требование описано в статье 77 Гражданско-процессуального кодекса. Дать заключение относительно соответствия аудиозаписи указанным параметрам может экспертиза аудиозаписи.
В случае открытого судебного заседания стороны, а также присутствующие граждане могут без согласия председательствующего проводить аудиозапись хода судебного заседания.
Для того чтобы ускорить процесс приобщения аудиозаписи к доказательствам, необходимо вместе с самой аудиозаписью представить дословную расшифровку содержания разговора и экспертное заключение, подтверждающее подлинность информации.
На какие вопросы отвечает эксперт в ходе экспертизы по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего)?
Экспертиза по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) требует не только специальных знаний, но и серьезного технического оснащения. Наш Центр имеет в наличии всю необходимую аппаратуру для проведения экспертизы аудиозаписи. Специалисты в области экспертизы аудиозаписи не только на высоком уровне проведут исследование, но и представят права заказчика на различных этапах судебного разбирательства.
Любой человек может заказать экспертизу по установлению принадлежности записанного голоса и звучащей речи конкретному лицу (идентификации говорящего) и в негосударственной компании. Преимущества негосударственной компании в области фоноскопической экспертизы очевидны: значительные возможности по внедрению, использованию новейших технических средств и методов исследования, отсутствие ведомственных инструкций делают фоноскопическую экспертизу более эффективной. При этом важно помнить, что заключения государственной и негосударственной компании имеют одинаковое значение.
Проведение экспертизы по уголовному делу
Согласно Постановлению Пленума Верховного Суда Российской Федерации от 21 декабря 2010 г. N 28 «О судебной экспертизе по уголовным делам» экспертиза по уголовному делу может быть проведена либо государственным экспертным учреждением, либо некоммерческой организацией, созданной в соответствии с Гражданским кодексом Российской Федерации и Федеральным законом «О некоммерческих организациях», осуществляющих судебно-экспертную деятельность в соответствии с принятыми ими уставами.
Коммерческие организации и лаборатории, индивидуальные предприниматели, образовательные учреждения, а также некоммерческие организации, для которых экспертная деятельность не является уставной, не имеют право проводить экспертизу по уголовному делу. Экспертиза, подготовленная указанными организациями в рамках уголовного процесса, может быть признана недопустимым доказательством, т.е. доказательством, полученным с нарушением требований процессуального закона.
Недопустимые доказательства не могут использоваться в процессе доказывания, в том числе, исследоваться или оглашаться в судебном заседании, и подлежат исключению из материалов уголовного дела.
Так как АНО «Судебный эксперт» является автономной некоммерческой организацией, а проведение судебных экспертиз является её основной уставной деятельностью (см. раздел «Документы организации»), то она имеет право проводить экспертизы в том числе и по уголовным делам.
Как узнать чей голос
Как насчет того, чтобы составить психологический фоторобот своего внутреннего голоса? Хочешь узнать, на кого он похож? Пройди тест!
Начало теста:
Варианты ответов:

Варианты ответов:

Варианты ответов:

Варианты ответов:

Варианты ответов:

Варианты ответов:

Варианты ответов:

Варианты ответов:
Идет подсчет результатов
Выберите, что Вас интересует:
Сообщить о нарушение
Ваше сообщение отправлено, мы постараемся разобраться в ближайшее время.
Попробуйте пройти эти тесты:
Сможете ли вы назвать имена всех этих легендарных артистов, популярных в СССР?
Тест о животных: Угадай зверя по его носу
Тест, который проверит вашу эрудицию: где вы на шкале от 0 до 12?
Тест на общие знания, который на 11/11 осилит лишь настоящий эрудит
Проверьте свой интеллект
Какое имя подходит вам по знаку зодиака
Если в этом тесте вы наберете 13/13, то вам пора поступать в Гарвард
Тест, который осилят лишь настоящие профи в мировой географии
Никто не может ответить больше чем на 7 из 10 вопросов в этом тесте на IQ
Большой тест на интеллект: узнай свой процент знаний
Докажите свою высокоинтеллектуальность, набрав в нашем тесте на общие знания 13/13
Простейший тест на IQ из нескольких вопросов
Тест на широкий кругозор: сможете ли вы ответить хотя бы на половину вопросов?
Угадайте воинские звания России по погонам
Если ответите на все вопросы нашего теста без ошибок, то можете считать себя уникумом с высоким IQ
Cколько лет вашей душе?
Вас можно назвать ходячей энциклопедией, если сможете набрать восемь правильных ответов
Сколько ты можешь выиграть в «Кто хочет стать миллионером?»
Тест: Узнайте в каком году вы должны были родиться на самом деле?
А насколько вы умны?
Подписывайтесь на наши странички! Обязательно делитесь с друзьями! Впереди много новых интересных тестов! Ежедневные добавления! Страницы: Яндекс Дзен, ВКонтакте, Одноклассники, Facebook
Новые тесты от Андрей
Bнeшнocть у разных знaков зoдиaкa
7 вопросов на проверку ваших способностей логически мыслить и сообразительность
Получите свое духовное послание!
7 вопросов из жизни в СССР. Сумеете ответить на все из них без ошибок?
10 вопросов по географии для тех, кто знает каждый уголок Земли
А вы знаете пословицы и их забытые окончания
10 вопросов для настоящих ценителей советского кинематографа
То, что вы видите на данном изображении, содержит в себе послание от ангелов
Обладаете ли вы личностью миллионера?
Бросьте вызов своей эрудиции и ответьте на 10 нестандартных вопросов из разных областей
Какой цвет волос тебе подходит по знаку зодиака
8 хитроумных вопросов на сообразительность и смекалку
Популярные тесты от Андрей
Помнишь, что ели в Советском Союзе?
Тест по фильмам СССР: Сможете пройти его на все 10/10? (Часть 2)
Никто не может угадать, какое из этих колец самое дорогое
Угадайте воинские звания России по погонам
Сколько ты можешь выиграть в «Кто хочет стать миллионером?»
У вас блестящая эрудиция, если сумеете дать 14 верных ответов из 14
Cколько лет вашей душе?
Тест на смекалку, в котором вы вряд ли наберете 8 правильных ответов, если ваш IQ ниже среднего
Тест по советским фильмам: Кто из актеров сказал эти известные всем слова?
Если сможете закончить 13 крылатых фраз, то вы настоящий интеллигент
Сможете ли вы узнать 20 людей, определивших ход истории?
У вас должно быть как минимум два образования, чтобы пройти этот тест хотя бы на 9/12
Популярные тесты
Сможете ли вы назвать имена всех этих легендарных артистов, популярных в СССР?
Тест о животных: Угадай зверя по его носу
Тест, который проверит вашу эрудицию: где вы на шкале от 0 до 12?
Тест на общие знания, который на 11/11 осилит лишь настоящий эрудит
Проверьте свой интеллект
Какое имя подходит вам по знаку зодиака
Если в этом тесте вы наберете 13/13, то вам пора поступать в Гарвард
Тест, который осилят лишь настоящие профи в мировой географии
Никто не может ответить больше чем на 7 из 10 вопросов в этом тесте на IQ
Большой тест на интеллект: узнай свой процент знаний
Докажите свою высокоинтеллектуальность, набрав в нашем тесте на общие знания 13/13
Простейший тест на IQ из нескольких вопросов
Тест на широкий кругозор: сможете ли вы ответить хотя бы на половину вопросов?
Угадайте воинские звания России по погонам
Если ответите на все вопросы нашего теста без ошибок, то можете считать себя уникумом с высоким IQ
Cколько лет вашей душе?
Вас можно назвать ходячей энциклопедией, если сможете набрать восемь правильных ответов
Сколько ты можешь выиграть в «Кто хочет стать миллионером?»
Тест: Узнайте в каком году вы должны были родиться на самом деле?
А насколько вы умны?
Преимущества
Можете встраивать тесты на Ваш сайт. Тест показывается нашем и других сайтах. Гибкие настройки результатов. Возможность поделиться тестом и результатами. Лавинообразный («вирусный») трафик на тест. Русскоязычная аудитория. Без рекламы!
Пользователям
Вам захотелось отдохнуть? Или просто приятно провести время? Выбирайте и проходите онлайн-тесты, делитесь результатом с друзьями. Проверьте, смогут они пройти также как Вы, или может лучше?
Внимание! Наши тесты не претендуют на достоверность – не стоит относиться к ним слишком серьезно!
Кто там? — Идентификация человека по голосу

Здравствуй, дорогой читатель!
Предлагаю твоему вниманию интересную и познавательную статью об отдельно взятом методе распознавания говорящего. Всего каких-то пару месяцев назад я наткнулся на статью о применении мел-кепстральных коэффициентов для распознавании речи. Она не нашла отклика, вероятно, из-за недостаточной структурированости, хотя материал в ней освещен очень интересный. Я возьму на себя ответственность донести этот материал в доступной форме и продолжить тему распознавания речи на Хабре.
Под катом я опишу весь процесс идентификации человека по голосу от записи и обработки звука до непосредственно определения личности говорящего.
Запись звука
Наша история начинается с записи аналогового сигнала с внешнего источника с помощью микрофона. В результате такой операции мы получим набор значений, которые соответствуют изменению амплитуды звука со временем. Такой принцип кодирования называется импульсно-кодовой модуляцией aka PCM (Pulse-code modulation). Как можно догадаться, «сырые» данные, полученные из аудио-потока, пока еще не годятся для наших целей. Первым делом нужно преобразовать непослушные биты в набор осмысленных значений — амплитуд сигнала. [1, с. 31] В качестве входных данных я буду использовать несжатый 16-битный знаковый (PCM-signed) wav-файл с частотой дискретизации 16 кГц.
Освежить знания про порядок байтов можно на википедии.
Обработка звука
Нормализация, на мой взгляд, — самый простой и эффективный алгоритм предварительной обработки звука. Существуют также масса других: «отрезающие» частоты выше или ниже заданной, сглаживающие и др.
Разделяй и властвуй
Даже при работе со звуком с минимально достаточной частотой дискретизации (16 кГц) размер уникальных характеристик для секундного образца звука просто огромен — 16000 значений амплитуд. Производить сколь-нибудь сложные операции над такими объемами данных не представляется возможным. Кроме того, не совсем понятно, как сравнивать объекты с разным количеством уникальных черт.
Для начала снизим вычислительную сложность задачи, разбив ее на меньшие по сложности подзадачи. Этим ходом убиваем сразу двух зайцев, ведь установив фиксированный размер подзадачи и усреднив результаты вычислений по всем задачам, получим наперед заданное количество признаков для классификации. 
На рисунке изображена «порезка» звукового сигнала на кадры длины N с половинным перекрытием. Необходимость в перекрытии вызвана искажением звука в случае, если бы кадры были расположены рядом. Хотя на практике этим приемом часто принебрегают для экономии вычислительных ресурсов. Следуя рекоммендациям [1, с. 28], выберем длину кадра равной 128 мс, как компромисс между точностью (длинные кадры) и скоростью (короткие кадры). Остаток речи, который не занимает полный кадр, можно заполнить нулями до желаемого размера или просто отбросить.
Для устранения нежелаетльных эффектов при дальнейшей обработке кадров, умножим каждый элемент кадра на особую весовую функцию («окно»). Результатом станет выделение центральной части кадра и плавное затухание амплитуд на его краях. Это необходимо для достижения лучших результатов при прогонке преобразования Фурье, поскольку оно ориентировано на бесконечно повторяющийся сигнал. Соответственно, наш кадр должен стыковаться сам с собой и как можно более плавно. Окон существует великое множество. Мы же будем использовать окно Хэмминга.
n — порядковый номер элемента в кадре, для которого вычисляется новое значение амплитуды
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
Дискретное преобразование Фурье
Следующим шагом будет получение кратковременной спектрограммы каждого кадра в отдельности. Для этих целей используем дискретное преобразование Фурье.
N — как и ранее, длина кадра (количество значений сигнала, измеренных за период)
xn — амплитуда n-го сигнала
Xk — N комплексных амплитуд синусоидальных сигналов, слагающих исходный сигнал
Кроме этого, возведем каждое значение Xk в квадрат для дальнейшего логарифмирования.
Переход к мел-шкале
На сегодняшний день наиболее успешными являются системи распознавания голоса, использующие знания об устройстве слухового аппарата. Несколько слов об этом есть и на Хабре. Если говорить вкратце, то ухо интерпретирует звуки не линейно, а в логарифмическом масштабе. До сих пор все операции мы проделывали над «герцами», теперь перейдем к «мелам». Наглядно представить зависимость поможет рисунок.
Как видно, мел-шкала ведет себя линейно до 1000 Гц, а после проявляет логарифмическую природу. Переход к новой шкале описывается несложной зависимостью.
m — частота в мелах
f — частота в герцах
Получение вектора признаков
Сейчас мы как никогда близко к нашей цели. Вектор признаков будет состоять из тех самых мел-кепстральных коэффициентов. Вычисляем их по формуле [2]
cn — мел-кепстральный коэффициент под номером n
Sk — амплитуда k-го значения в кадре в мелах
K — наперед заданное количество мел-кепстральных коэффициэнтов
n ∈ [1, K]
Как правило, число K выбирают равным 20 и начинают отсчет с 1 из-за того, что коэффициент c0 несет мало информации о говорящем, так как является, по сути, усреднением амплитуд входного сигнала. [2]
Так кто же все-таки говорил?
Последней стадией является классификация говорящего. Классификация производится вычислением меры схожести пробных данных и уже известных. Мера схожести выражается расстоянием от вектора признаков пробного сигнала до вектора признаков уже классифицированного. Нас будет интересовать наиболее простое решение — расстояние городских кварталов.
Такое решение больше подходит для векторов дискретной природы, в отличие от расстояния Евклида.
Внимательный читатель наверняка помнит, что автор в начале статьи упоминал про усреднение признаков речевых кадров. Итак, восполняя этот пробел, завершаю статью описанием алгоритма нахождения усредненного вектора признаков для нескольких кадров и нескольких образцов речи.
Кластеризация
Нахождение вектора признаков для одного образца не составит труда: такой вектор представляется как среднее арифметическое векторов, характеризующих отдельные кадры речи. Для повышения точности распознавания просто необходимо усреднять результаты не только между кадрами, но и учитывать показатели нескольких речевых образцов. Имея несколько записей голоса, разумно не усреднять показатели к одному вектору, а провести кластеризацию, например с помощью метода k-средних.
Итоги
Я всегда рад полезным комментариям по поводу улучшения материала. Спасибо за внимание.



