Типы данных SQL
Типы данных SQL
Типы данных SQL разделяются на три группы:
— строковые;
— с плавающей точкой (дробные числа);
— целые числа, дата и время.
Типы данных MySQL
Типы данных MySQL разделяются на следующие типы:
Типы данных Oracle
Типы данных Oracle разделяются на следующие группы:
ANSI SQL стандарт распознает только текст и число, в то время как большинство коммерческих программ используют другие специальные типы, такие как DATЕ и TIME — фактически почти стандартные типы. Некоторые пакеты также поддерживают такие типы, как, например, MONEY и BINARY. Типы данных, распознаваемые с помощью ANSI, состоят из строк символов и различных типов чисел, которые могут классифицироваться как точные числа и приблизительные числа.
CHARACTER(length) определяет спецификацию строк символов, где length задает длину строк заданного типа. Значения этого типа должны быть заключены в одиночные кавычки. Большинство реализаций поддерживают строки переменной длины для типов данных VARCHAR и LONG VARCHAR (или просто LONG).
В то время, как поле типа CHAR всегда может распределить память для максимального числа символов, которое может сохраняться в поле, поле VARCHAR при любом количестве символов может распределить только определенное количество памяти, чтобы сохранить фактическое содержание поля, хотя SQL может установить некоторое дополнительное пространство памяти, чтобы следить за текущей длиной поля. Поле VARCHAR может быть любой длины, включая реализационно-определяемый максимум. Этот максимум может меняться от 254 до 2048 символов для VARCHAR и до 16000 символов для LONG. LONG обычно используется для текста пояснительного характера или для данных, которые не могут легко сжиматься в простые значения полей; VARCHAR может использоваться для любой текстовой строки, чья длина может меняться.
Извлечение и модифицирование полей VARCHAR — более сложный, и, следовательно, более медленный процесс, чем извлечение и модифицирование полей CHAR. Кроме того, некоторое количество памяти VARCHAR, остается всегда неиспользованной для гарантии вмещения всей длины строки. При использовании таких типов следует предусматривать возможность полей к объединению с другими полями.
Точные числовые типы — это числа, с десятичной точкой или без десятичной точки, которые могут представляться в виде [+|-] [. ] и специфицироваться как:
DECIMAL(precision [, scale]) — аргумент размера имеет две части: точность и масштаб. Масштаб не может превышать точность. Точность указывает сколько значащих цифр имеет число. Масштаб указывает максимальное число цифр справа от десятичной точки. Масштаб = нулю делает поле эквивалентом целого числа.
NUMERIC(precision [, scale]) — такое же как DECIMAL за исключением того, что максимальное десятичное не может превышать аргумента точности
INTEGER — число без десятичной точки. Эквивалентно DECIMAL, но без цифр справа от десятичной точки, т.е. с масштабом равным 0. Аргумент размера не используется (он автоматически устанавливается в реализационно-зависимое значение).
SMALLINT — такое же как INTEGER, за исключением того, что, в зависимости от реализации, размер по умолчанию может ( или не может ) быть меньше чем INTEGER.
Приблизительные числовые типы — это числа в показательной (экспоненциальной по основанию 10) записи, представляемые как Е и специфицирущиеся следующим образом:
FLOAT[(precision)] — число с плавающей запятой. Аргумент размера состоит из одного числа, определяющего минимальную точность.
REAL — такое же как FLOAT, за исключением того, что никакого аргумента размера не используется. Точность устанавливается реализационно-зависимой по умолчанию.
DOUBLE PRECISION — такое же как REAL, за исключением того, что реализационно-определяемая точность для DOUBLE PRECISION должна превышать реализационно-определяемую точность REAL.
Типы данных Access
Типы данных Access разделяются на следующие группы:
Типы данных SQL Server
Типы данных, используемые в SQL Server:
Типы данных PostgreSQL
База данных PostgreSQL поддерживает большинство типов данных SQL2003 плюс огромный набор типов для хранения пространственных и геометрических данных. PostgreSQL может похвастаться богатым набором операторов и функций, специально предназначенных для геометрических типов данных. Сюда входят такие средства, как поворот, поиск пересечений и масштабирование. В PostgreSQL также есть поддержка дополнительных версий существующих типов данных, которые характерны тем, что занимают меньше места на диске, чем соответствующие исходные версии. Например, в PostgreSQL предлагается несколько вариантов типа INTEGER для хранения больших и небольших чисел, соответственно занимающих больше или меньше места.
Вы должны войти, чтобы оставить комментарий.
SQL для чайников. Реляционные БД. Типы данных
Всем доброго дня, пикабушники и пикабушницы.
Пообщавшись со многими людьми из сферы IT как-то напросилась мысль, что многие хотели бы знать SQL, но либо учебники скучные, то ли нет понимания, с чего начинать.
Оставлю это здесь, может кому-то пригодится.
Для начала, надо разобрать, что же такое SQL, а так же, где, как и зачем применяется.
Считаю справедливым, что нужно дать определение РБД:
Напоминает адресную или телефонную книгу, в которой есть зависимости.

Такая адресная книга называется двухмерной (строка и столбец) таблицей информации.
БД обычно не состоят из одной таблицы, поэтому, мы добавим еще одну:

Ничего не изменилось: так же, набор атрибутов у определенных «лиц».
Если мы захотим найти всю информацию по этим трем людям, мы получим следующее:

Кроме того, первичные ключи гарантируют, что ваши данные имеют определенную целостность.
В SQL типы данных разделяются на три группы: строковые, с плавающей точкой (дробные числа) и целые числа, дата и время.

Типы с плавающей точкой (дробные числа) и целые числа:

Целые числа, дата и время:
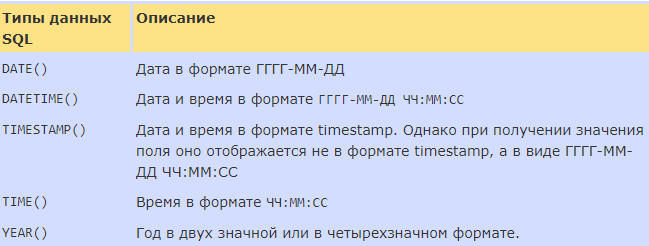
Вернемся к определению SQL.
P.S.: если все же полезная инфа, могу написать еще парочку статей о простых запросах Select с условиями Where. Напишите в комментарии.
Дубликаты не найдены

Лига программистов
309 постов 5.5K подписчик
Правила сообщества
Правило 2. При публиковании поста ставим корректные теги, передающие смысл публикации.
Может они из других баз пришли, не таких классических?)
Они пришли из «хуяк-хуяк и в продакшн». Я столько таких долбоёбов повидал, что даже немножко страшно.
хм, в SAP повсеместно используются буквенно-числовые индексы.
Потому что если мы откатимся на 15 лет назад, то тогда САП был самый модный тренд, и если сейчас всякие сантехники в вебчик идут, то тогда шли в тот самый сап. Оттуда и общий уровень АБАП-кода, ну и культуры кода тоже. И скакали с места на место постоянно, а пришедший после тебя не мог в твоём говно-спагетти-коде разобраться.
но ведь сап сам по себе так построен. Хоть убейся, но индексы будут с буквами, причем в стандартных объектах. Ну во так у него заложено. Зато он быстрый, но очень дорогой (если говорить о BW+HANA)
Я видел, когда ключевое поле в таблице назначали по 7 char-полям.
Если б я не знал что такое первичный ключ, то ничего бы не понял.
Если кто-то действительно хочет изучить SQL, рекомендую начать не с постов на пикабу, а с вебинара MS 10774 Гурьянова и Самородова. Курс примерно 2012 года, но всё актуально и на сегодняшний день.
Практиковаться после курсов можно тут: https://www.sql-ex.ru/
Плюс на sql.ru есть неплохие статьи, когда уже более конкретно человек определится. То что в посте вообще смысла не несет.
ты на собеседование хоть раз ходил?
Если бы я не знал материал, я бы ничего не понял.
Если бы мне нужно было бы изучить этот материал, я бы полез в книги, ютуб, стаковерфлоу, но не сюда.
Это два моих скромных совета
Упоминаешь «атрибут», а что это такое? Потом напишешь «кортеж» и догадывайтесь сами, что это?

Што? Какой-то непонятный изъёб, дабы придать тексту флёр академичности. Проще будь, ТС, тут тебе не хабр с яйцеголовыми. И да, хватит уже путать понятия данных и информации. Хранилища информации называются базами знаний. А БД в самом своём названии содержит подсказку.
И ANSI синтаксис таки все поддерживают, нюансы определенных систем можно уже на ходу узнать. Реальная разница начинается в расширениях типа PL или Transact
Отвратительно. Тут же дети, прошу не вываливать вот это вот тут.
это общеобзорная статья на то, что такое SQL. Примеры обязательно будут, если нужно продолжение)
Не нужно. В инете этого полно.
Зачем это здесь? есть профильные сайты на которых можно нормально и грамотно учиться.
Почему каждый кто найдёт информацию в интернете начинает воображать себя невьебенным учителем?
Есть люди которые не знают много чего. Кто-то не знает как двигатель внутреннего сгорания работает, кто-то не знает как работает процессор компьютера, и я не знаю как перекрасить волосы в другой цвет.
Вопрос в том, зачем об этом писать тут? тем более так некачественно. Людям ведь если это не нужно, то зачем им тратить на это время? а если нужно, то они без труда смогут найти качественную информацию по интересующей их теме. Но они ведь не будут искать на пикабу эту информацию и не факт что она вообще будет хорошего качества.
Кроме того, первичные ключи гарантируют, что ваши данные имеют определенную целостность.
Первичный ключ? для этого вообще отдельная статья нужна а у тебя несколько строк. У меня от такой статьи возникло больше вопросов, чем ответов.
Ты б ещё сопромат сюда притащил!



Раньше странно было наблюдать, почему при автоматизации бизнес процессов заказчики боятся баз данных
Цепляние за эксель у многих происходит до последнего
Вроде бы уже все, можно отпустить и двигаться дальше. Но нет. Давайте лучше эксель
Потом понял, что они даже по своему правы
Эксель для них это последний бастион, где они еще удерживают ситуацию под контролем. Можно залезть ручками в файл, настроить фильтры, поковыряться. Если надо, то что-то подправить в формулах и связях между таблицами
Переход к базе данных это следующий уровень сложности, знаний для контроля над которым просто нет
Тут они уже нутром понимают, что обратной дороги не будет. Придётся зависеть от этих мутных ИТ-шников, с их sql запросами и прочей магией
А база данных это где?
Еще хорошо если на локальном сервере. По крайне мере может покажут стационарный комп с мигающими лампочками. В мозгах может появится успокаивающая ассоциация, что этот ящик и есть база данных. Тогда его можно в охраняемую комнату запереть и спать спокойно.
А если база данных в «облаке»?
В газетах вон постоянно пишут про хакеров и как из облаков данные утекают
Нет, нам такой прогресс не нужен. Лучше эксель
Тут все надежно, проверено мудростью предков, и есть панацея от всех проблем: ctrl+alt+delete
Когда для тебя SQL это не просто буквы



О печальной защите информации в 2017 году
В данном посте я хочу поговорить не про гигантов типа Google, Яндекс или ВК, а про обычные компании с которыми мы работаем или которые не так известны.
Несмотря на кучу законов типа ФЗ-152 уровень защищенности персональных (и не только) данных к сожалению переживает по моим наблюдениям не лучшие свои времена.
К сожалению утечки встречаются почти на каждом шагу, большинство по работе. Я хочу рассказать о найденных мной уязвимостях в 2017 году.
В начале этого года попросили проверить одну Windows программу с целью узнать, что она вообще делает. Программа позиционировала себя как обратная связь клиента с фирмой, своеобразный такой чат.
Вооружившись VirtualBox с установленным внутри WireShark и другими средствами мониторинга начал следить за программой, исследовал формочки приложения. В WireShark промелькнул HTTP-запрос, отправляющий сообщение на сервер. Так же обнаружил и HTTP-запрос, получающий сообщения с сервера. Немного поразбежавшись, обнаруживаем, что никакой авторизации на стороне сервера нет. Получаем сразу 2 уязвимости. Мы можем читать сообщения любого пользователя, включая, что пишут админу, а так же от имени пользователя отправлять сообщения другому пользователю.
На следующую уязвимость в конце зимы или весной в 2017 году я наткнулся совершенно случайно с помощью рекламы в Яндекс-Директе.
Попалась на глаза мне контекстная реклама одной фирмы, которая говорила, что есть филиалы во многих городах РФ. Что-то тогда меня заинтересовало и я открыл их сайт.
Там открыл форму обратной связи.
С удивлением замечаю попадаю на сайт без домена, а только IP-адрес сервера.
Стало любопытно, а что работает на этой машинке? Проверяю порт FTP и… захожу под гостем. Куча всяких файлов, рабочая WEB-папка со страницами сайта. Есть немножко бэкапов. С виду сервер использовался как или помойка или как тестовый сервер.
Открываем файл конфигурации из Web-папки … Видим логин и пароль от FTP-другого сервера.
Проверяем… И попадаем уже во второй сервер…
Там тоже поднят WEB-сервер и вообще файлов намного больше… на 200 гигабайт с лишним. В основном это конечно бэкапы баз, но и очень много рабочих и свежих документов.
Внутри конфига WEB-сервера уже засвечивается и SQL-сервер с логином и паролем, который крутится на этом сервере. И да. На него тоже можно попасть.
Итог: получаем утечку в из крупной фирмы с возможностью исказить/уничтожить информацию и бэкапы баз данных.
Также в этом году для работы потребовалось создать парсер сайта довольно большой бюджетной организации для формирования БД (около миллиона строк в 3 таблицах), что бы уменьшить ручной труд и постоянные запросы к сайту. Сам сайт тоже тот еще тормоз, поэтому создание парсера было логичным решением, что бы получить сразу готовые таблицы и всегда иметь их под рукой.
В голове вместе с алгоритмом парсера и количество срок кода росла также лень всё это делать. Тогда я решил проверить теорию с предыдущим сервером. И.. Вы не поверите! Ситуация практически повторилась! Мы опять попали на FTP сервер, но на этот раз там лежал файл VPNRouter_64.vmdk. Виртуальная машинка.
Немного колдуем над файлом и получаем доступ к разделу виртуального диска внутри машинки.
Самое интересное, это папка OpenVPN с настроенной конфигурацией и сертификатами.
Копируем на свой комп, подключаемся, и… Бинго! Мы внутри защищенной сети.
Смотрим какой нам присвоил сервер виртуальный IP.
Открываем терминал, запускаем nmap сканируем всю подсеть на 80,21,1433 порты.
Есть несколько компьютеров с такими открытыми портами!
И опять нас радостно встречает FTP без пароля на одном из серверов!
А дальше классика. Открываем Web.config, получаем строку подключения к серверу и с помощью dBeaver мы получаем доступ к базе данных внутри сети. Что еще интереснее, данная комбинация подошла и на другие SQL-сервера внутри этой сети. Один пароль на все сервера (всего их было 3-5 серверов, уже не помню). И это довольно крупная бюджетная организация для нашего региона!
Опять же возможность положить сайты, совершить утечку персональных данных (я там себя нашёл), исказить/удалить.
Сами персональные данные мне уже не интересны. Я с ними работаю каждый день, допуск к базе своего региона (ну или большей её части) у меня есть и так.
Еще один случай опять же на работе, опять же в этом году.
Другая бюджетная организация дала VPN (L2TP) доступ и программку которая работает с их сервером, обмен с базой данных.
В таком режиме мы уже работаем давно, но программист написавший программу уже уволился, а неудобства с программой проявляются все сильнее и мысли написать свою программу типа плагина или хотя бы нужные скрипты. И тогда я решил провести один эксперимент, а именно попробовать подключиться не через их прогу, а через редактор БД. Выдергиваю, по какому адресу их программа стучится, вбиваю в редактор БД, и… сервер нас впустил! Ему хватило подключения по VPN и доверительное соединение! Мы опять получаем доступ к серверу ко всем базам, которые там находятся со всеми вытекающими, куда по идее мы не должны были попасть.
Похожая ситуация и в самой корпоративной сети, опять же в этом году.
Дали программу, файл реестра, внутри которого… Логин sa, пароль 111111As…. Доступ из внешки… Ну хоть не на стандартном порту. А на нем так же крутиться персональная информация! Любой админ из корпоративной сети сути может увидеть инфу другого филиала через SQL-редактор, к которой он не должен иметь доступа, а так же изменить/удалить всю БД! А то что изначально дали доступ без защищенного канала еще хуже! Благо щас перевели программу на Vipnet, но пару месяцев назад доступ по внешнему IP еще был, может и до сих пор есть.
Недавно проводил исследование одного Android-приложения (мой предыдущий пост), там такая же плачевная ситуация. Любой школьник может получить доступ к информации без авторизации, слить бюджет на СМС, зафлудить СМС чей нибудь телефон, исказить рейтинг, слить базу данных. Так же существует возможность получить права баристы простым брутом пароля!
Это всё печально дамы и господа. Давайте, мы будем относиться к защите наших серверов/ПК/телефонов более серьезно. Для проникновения внутрь не понадобились никакие эксплоиты, хакерские навыки. Только штатные программы и любознательность.
А сколько подобных серверов с открытым доступом в интернете? А сколько еще таких дырявых приложений в Маркете? Наверно тысячи, десятки тысяч.
Вполне возможно, Вы так же сталкивались с похожими ситуациями, надеюсь без злых намерений.
Многие этим профессионально занимаются, пишут ботов которые ползают по интернету, пробивают стандартные порты, брутят по словарю, ломают роутеры, IP-камеры, увеличивая армию ботов. С такими ботами встречался и я, точнее мой Firewall и было занятно наблюдать как пытались подобрать пароль от моей базы по примерно по 5-10 запросов в секунду.
Так же попадались боты которые пытались ломануть мой FTP и VNC сервер из разных стран.
Обнаружив эти попытки в логах, я убрал компы за NAT и с тех пор я держу все порты закрытыми, оставив только порт для VPN-соединения, а при, необходимости временно доступа другим людям, открываю временно их на нестандартных портах. Для постоянно доступа использую OpenVPN и генерирую сертификаты на каждое устройство.
Итак. Для минимальной безопасности:
1. Не держите FTP сервер с возможностью подключаться анонимусом. Не держите на FTP какую либо инфу, позволяющая скомпрометировать другие сервера. Конечно, если это Web-сервер и через FTP обновляется его содержимое, то дайте ему минимальные права, если его вдруг вскроют.
2. Не используйте простые пароли, которые можно легко сбрутить. Поверьте, боты не спят и рано или поздно могут приняться за ваш сервер, если он виден извне.
3. Используйте защищенное соединение. Если это не предоставляется возможным, вешайте службы на нестандартные порты. Такие порты найти сложнее и сканировать один комп относительно долго. Если есть настроенный Firewall, то вполне может сработать тревога сканирования портов и при их прозвоне ботом, фаервол начнет посылать все попытки подключения бота в лес, а порты ботом так и не будут найдены.
4. Если возможно, старайтесь в Андроид-приложениях шифровать все HTTP-запросы. Например http://127.0.0.1/web?query=vcXGregfds4r5f3r456sdr32vdf-6t и ответ получать примерно такой же. Через снифер уже не будет видна какая-либо зависимость от запросов и большинство любителей это уже может остановить. В идеале еще прикрутить защищенное соединение, но многих останавливает, что SSL-сертификаты платные. Можно еще использовать сокеты.
5. Не оставляйте в приложениях права админа, например в веб-приложениях, десктопных. Старайтесь давать минимальные права приложениям. Фукнции авторизации желательно вешать на сервер, а дальше посылать только ID-сессии, а не UserID. При обмене данными всегда проверять авторизована ли машина или нет. Особенно это касается Web- и Android-приложении.
6. Периодически проверяйте логи приложений, а так же лог фаервола.
7. Сервера желательно прятать за NAT, а в некоторых случаях (например, если это сервер с персональными данными или где проводятся финансовые операции) за двойной NAT.
8. Ну про своевременную установку патчей и обновлений, я думаю не стоит объяснять.
9. Ну и конечно следите за новостями о вирусных угрозах, эпидемиях, новых шифровальщиках
Желаю всем в следующем году стабильных линков, отсутствие зловредов и хороших клиентов. Сделаем наши сервера, базы данных и приложения более защищенными.
Памятка/шпаргалка по SQL

Доброго времени суток, друзья!
Изучение настоящей шпаргалки не сделает вас мастером SQL, но позволит получить общее представление об этом языке программирования и возможностях, которые он предоставляет. Рассматриваемые в шпаргалке возможности являются общими для всех или большинства диалектов SQL.
Для более полного погружения в SQL рекомендую изучить эти руководства по MySQL и PostgreSQL от Метанита. Они хороши тем, что просты в изучении и позволяют быстро начать работу с названными СУБД.
При обнаружении ошибок, опечаток и неточностей, не стесняйтесь писать мне в личку.
Содержание
Что такое SQL?
SQL — это язык структурированных запросов (Structured Query Language), позволяющий хранить, манипулировать и извлекать данные из реляционных баз данных (далее — РБД, БД).
Почему SQL?
Процесс SQL
При выполнении любой SQL-команды в любой RDBMS (Relational Database Management System — система управления РБД, СУБД, например, PostgreSQL, MySQL, MSSQL, SQLite и др.) система определяет наилучший способ выполнения запроса, а движок SQL определяет способ интерпретации задачи.
В данном процессе участвует несколького компонентов:
Классический движок обрабатывает все не-SQL-запросы, а движок SQL-запросов не обрабатывает логические файлы.
Команды SQL
| N | Команда | Описание |
|---|---|---|
| 1 | CREATE | Создает новую таблицу, представление таблицы или другой объект в БД |
| 2 | ALTER | Модифицирует существующий в БД объект, такой как таблица |
| 3 | DROP | Удаляет существующую таблицу, представление таблицы или другой объект в БД |
| N | Команда | Описание |
|---|---|---|
| 1 | SELECT | Извлекает записи из одной или нескольких таблиц |
| 2 | INSERT | Создает записи |
| 3 | UPDATE | Модифицирует записи |
| 4 | DELETE | Удаляет записи |
| N | Команда | Описание |
|---|---|---|
| 1 | GRANT | Наделяет пользователя правами |
| 1 | REVOKE | Отменяет права пользователя |
Обратите внимание: использование верхнего регистра в названиях команд SQL — это всего лишь соглашение, большинство СУБД нечувствительны к регистру. Тем не менее, форма записи инструкций, когда названия команд пишутся большими буквами, а названия таблиц, колонок и др. — маленькими, позволяет быстро определять назначение производимой с данными операции.
Что такое таблица?
Данные в СУБД хранятся в объектах БД, называемых таблицами (tables). Таблица, как правило, представляет собой коллекцию связанных между собой данных и состоит из определенного количества колонок и строк.
Таблица — это самая распространенная и простая форма хранения данных в РБД. Вот пример таблицы с пользователями (users):
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Что такое поле?
Каждая таблица состоит из небольших частей — полей (fields). Полями в таблице users являются userId, userName, age, city и status. Поле — это колонка таблицы, предназначенная для хранения определенной информации о каждой записи в таблице.
Что такое запись или строка?
Запись или строка (record/row) — это любое единичное вхождение (entry), существующее в таблице. В таблице users 5 записей. Проще говоря, запись — это горизонтальное вхождение в таблице.
Что такое колонка?
Что такое нулевое значение?
Ограничения
Ограничения (constraints) — это правила, применяемые к данным. Они используются для ограничения данных, которые могут быть записаны в таблицу. Это обеспечивает точность и достоверность данных в БД.
Ограничения могут устанавливаться как на уровне колонки, так и на уровне таблицы.
Среди наиболее распространенных ограничений можно назвать следующие:
Любое ограничение может быть удалено с помощью команды ALTER TABLE и DROP CONSTRAINT + название ограничения. Некоторые реализации предоставляют сокращения для удаления ограничений и возможность отключать ограничения вместо их удаления.
Целостность данных
В каждой СУБД существуют следующие категории целостности данных:
Нормализация БД
Нормализация — это процесс эффективной организации данных в БД. Существует две главных причины, обуславливающих необходимость нормализации:
Нормализация предполагает соблюдение нескольких форм. Форма — это формат структурирования БД. Существует три главных формы: первая, вторая и, соответственно, третья. Я не буду вдаваться в подробности об этих формах, при желании, вы без труда найдете необходимую информацию.
Синтаксис SQL
Примеры синтаксиса
Типы данных
Каждая колонка, переменная и выражение в SQL имеют определенный тип данных (data type). Основные категории типов данных:
Точные числовые
Приблизительные числовые
| Тип данных | От | До |
|---|---|---|
| float | -1.79E + 308 | 1.79E + 308 |
| real | -3.40E + 38 | 3.40E + 38 |
Дата и время
| Тип данных | От | До |
|---|---|---|
| datetime | Jan 1, 1753 | Dec 31, 9999 |
| smalldatetime | Jan 1, 1900 | Jun 6, 2079 |
| date | Дата сохраняется в виде June 30, 1991 | |
| time | Время сохраняется в виде 12:30 P.M. |
Строковые символьные
| N | Тип данных | Описание |
|---|---|---|
| 1 | char | Строка длиной до 8,000 символов (не-юникод символы, фиксированной длины) |
| 2 | varchar | Строка длиной до 8,000 символов (не-юникод символы, переменной длины) |
| 3 | text | Не-юникод данные переменной длины, длиной до 2,147,483,647 символов |
Строковые символьные (юникод)
| N | Тип данных | Описание |
|---|---|---|
| 1 | nchar | Строка длиной до 4,000 символов (юникод символы, фиксированной длины) |
| 2 | nvarchar | Строка длиной до 4,000 символов (юникод символы, переменной длины) |
| 3 | ntext | Юникод данные переменной длины, длиной до 1,073,741,823 символов |
Бинарные
| N | Тип данных | Описание |
|---|---|---|
| 1 | binary | Данные размером до 8,000 байт (фиксированной длины) |
| 2 | varbinary | Данные размером до 8,000 байт (переменной длины) |
| 3 | image | Данные размером до 2,147,483,647 байт (переменной длины) |
Смешанные
| N | Тип данных | Описание |
|---|---|---|
| 1 | timestamp | Уникальные числа, обновляющиеся при каждом изменении строки |
| 2 | uniqueidentifier | Глобально-уникальный идентификатор (GUID) |
| 3 | cursor | Объект курсора |
| 4 | table | Промежуточный результат, предназначенный для дальнейшей обработки |
Операторы
Оператор (operators) — это ключевое слово или символ, которые, в основном, используются в инструкциях WHERE для выполнения каких-либо операций. Они используются как для определения условий, так и для объединения нескольких условий в инструкции.
Арифметические
| Оператор | Описание | Пример |
|---|---|---|
| + (сложение) | Сложение значений | a + b = 30 |
| — (вычитание) | Вычитание правого операнда из левого | b — a = 10 |
| * (умножение) | Умножение значений | a * b = 200 |
| / (деление) | Деление левого операнда на правый | b / a = 2 |
| % (деление с остатком/по модулю) | Деление левого операнда на правый с остатком (возвращается остаток) | b % a = 0 |
Операторы сравнения
Логические операторы
| N | Оператор | Описание |
|---|---|---|
| 1 | ALL | Сравнивает все значения |
| 2 | AND | Объединяет условия (все условия должны совпадать) |
| 3 | ANY | Сравнивает одно значение с другим, если последнее совпадает с условием |
| 4 | BETWEEN | Проверяет вхождение значения в диапазон от минимального до максимального |
| 5 | EXISTS | Определяет наличие строки, соответствующей определенному критерию |
| 6 | IN | Выполняет поиск значения в списке значений |
| 7 | LIKE | Сравнивает значение с похожими с помощью операторов подстановки |
| 8 | NOT | Инвертирует (меняет на противоположное) смысл других логических операторов, например, NOT EXISTS, NOT IN и т.д. |
| 9 | OR | Комбинирует условия (одно из условий должно совпадать) |
| 10 | IS NULL | Определяет, является ли значение нулевым |
| 11 | UNIQUE | Определяет уникальность строки |
Выражения
Выражение (expression) — это комбинация значений, операторов и функций для оценки (вычисления) значения. Выражения похожи на формулы, написанные на языке запросов. Они могут использоваться для извлечения из БД определенного набора данных.
Базовый синтаксис выражения выглядит так:
Существуют различные типы выражений: логические, числовые и выражения для работы с датами.
Логические
Логические выражения извлекают данные на основе совпадения с единичным значением.
Предположим, что в таблице users имеются следующие записи:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Выполняем поиск активных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Числовые
Используются для выполнения арифметических операций в запросе.
Простой пример использования числового выражения:
Также существует несколько встроенных функций для работы со строками:
Выражения для работы с датами
Эти выражения, как правило, возвращают текущую дату и время.
Другие функции для получения текущей даты и времени:
Функции для разбора даты и времени:
Функции для манипулирования датами:
Создание БД
Условие IF NOT EXISTS позволяет избежать получения ошибки при попытке создания БД, которая уже существует.
Название БД должно быть уникальным в пределах СУБД.
Получаем список БД:
Удаление БД
Условие IF EXISTS позволяет избежать получения ошибки при попытке удаления несуществующей БД.
Обратите внимание: при удалении БД уничтожаются все данные, которые в ней хранятся, так что будьте предельно внимательны при использовании данной команды.
Проверяем, что БД удалена:
Выбор БД
Создание таблицы
Проверяем, что таблица была создана:
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| userId | int(11) | NO | PRI | ||
| userName | varchar(20) | NO | |||
| age | int(11) | NO | |||
| city | varchar(20) | NO | |||
| status | varchar(8) | YES | NULL |
Удаление таблицы
Обратите внимание: при удалении таблицы, навсегда удаляются все хранящиеся в ней данные, индексы, триггеры, ограничения и разрешения, так что будьте предельно внимательны при использовании данной команды.
Удаляем таблицу users :
Добавление колонок
Названия колонок можно не указывать, однако, в этом случае значения должны перечисляться в правильном порядке.
Во избежание ошибок, рекомендуется всегда перечислять названия колонок.
В таблицу можно добавлять несколько строк за один раз.
Также, как было отмечено, при добавлении строки названия полей можно опускать:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 25 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Заполнение таблицы с помощью другой таблицы
Выборка полей
Для выборки всех полей используется такой синтаксис:
| userId | userName | age |
|---|---|---|
| 1 | Igor | 25 |
| 2 | Vika | 26 |
| 3 | Elena | 27 |
| 4 | Oleg | 28 |
Предложение WHERE
Обратите внимание: строки в предложении WHERE должны быть обернуты в одинарные кавычки ( » ), а числа, напротив, указываются как есть.
Операторы AND и OR
Конъюнктивный оператор AND и дизъюнктивный оператор OR используются для соединения нескольких условий при фильтрации данных.
Возвращаемые записи должны удовлетворять всем указанным условиям.
Возвращаемые записи должны удовлетворять хотя бы одному условию.
Сделаем выборку тех же полей неактивных пользователей или пользователей, младше 27 лет:
Обновление полей
Обновим возраст пользователя с именем Igor :
Удаление записей
Удалим неактивных пользователей:
Предложения LIKE и REGEX
LIKE
Предложение LIKE используется для сравнения значений с помощью операторов с подстановочными знаками. Существует два вида таких операторов:
% означает 0, 1 или более символов. _ означает точно 1 символ.
| N | Инструкция | Результат |
|---|---|---|
| 1 | WHERE col LIKE ‘foo%’ | Любые значения, начинающиеся с foo |
| 2 | WHERE col LIKE ‘%foo%’ | Любые значения, содержащие foo |
| 3 | WHERE col LIKE ‘_oo%’ | Любые значения, содержащие oo на второй и третьей позициях |
| 4 | WHERE col LIKE ‘f%%’ | Любые значения, начинающиеся с f и состоящие как минимум из 1 символа |
| 5 | WHERE col LIKE ‘%oo’ | Любые значения, оканчивающиеся на oo |
| 6 | WHERE col LIKE ‘_o%o’ | Любые значения, содержащие o на второй позиции и оканчивающиеся на o |
| 7 | WHERE col LIKE ‘f_o’ | Любые значения, содержащие f и o на первой и третьей позициях, соответственно, и состоящие из трех символов |
Сделаем выборку неактивных пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 4 | Oleg | 28 | Moscow | inactive |
Сделаем выборку пользователей 30 лет и старше:
REGEX
Предложение REGEX позволяет определять регулярное выражение, которому должна соответствовать запись.
В регулярное выражении могут использоваться следующие специальные символы:
Сделаем выборку пользователей с именами Igor и Vika :
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
Предложение TOP / LIMIT / ROWNUM
Данные предложения позволяют извлекать указанное количество или процент записей с начала таблицы. Разные СУБД поддерживают разные предложения.
Сделаем выборку первых трех пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
Параметр offset (смещение) определяет количество пропускаемых записей. Например, так можно извлечь первых двух пользователей, начиная с третьего:
Предложения ORDER BY и GROUP BY
ORDER BY
Предложение ORDER BY используется для сортировки данных по возрастанию ( ASC ) или убыванию ( DESC ). Многие СУБД по умолчанию выполняют сортировку по возрастанию.
Обратите внимание: колонки для сортировки должны быть указаны в списке колонок для выборки.
Сделаем выборку пользователей, отсортировав их по городу и возрасту:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 2 | Vika | 26 | Ekaterinburg | inactive |
| 3 | Elena | 27 | Ekaterinburg | active |
| 1 | Igor | 25 | Moscow | active |
| 4 | Oleg | 28 | Moscow | inactive |
Теперь выполним сортировку по убыванию:
Определим собственный порядок сортировки по убыванию:
GROUP BY
Сгруппируем активных пользователей по городам:
Ключевое слово DISTINCT
Ключевое слово DISTINCT используется совместно с инструкцией SELECT для возврата только уникальных записей (без дубликатов).
Сделаем выборку городов проживания пользователей:
Соединения
Соединения (joins) используются для комбинации записей двух и более таблиц.
| orderId | date | userId | amount |
|---|---|---|---|
| 101 | 2021-06-21 00:00:00 | 2 | 3000 |
| 102 | 2021-06-20 00:00:00 | 2 | 1500 |
| 103 | 2021-06-19 00:00:00 | 3 | 2000 |
| 104 | 2021-06-18 00:00:00 | 3 | 1000 |
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
Существуют разные типы объединений:
Предложение UNION
Однако, они могут быть разной длины.
Объединим наши таблицы users и orders :
| userId | userName | amount | date |
|---|---|---|---|
| 1 | Igor | NULL | NULL |
| 2 | Vika | 3000 | 2021-06-21 00:00:00 |
| 2 | Vika | 1500 | 2021-06-20 00:00:00 |
| 3 | Elena | 2000 | 2021-06-19 00:00:00 |
| 3 | Elena | 1000 | 2021-06-18 00:00:00 |
| 4 | Alex | NULL | NULL |
Предложение UNION ALL
Существует еще два предложения, похожих на UNION :
Синонимы
Синонимы (aliases) позволяют временно изменять названия таблиц и колонок. «Временно» означает, что новое название используется только в текущем запросе, в БД название остается прежним.
Синтаксис синонима таблицы:
Синтаксис синонима колонки:
Пример использования синонимов таблиц:
| userId | userName | age | amount |
|---|---|---|---|
| 2 | Vika | 26 | 3000 |
| 2 | Vika | 26 | 1500 |
| 3 | Elena | 27 | 2000 |
| 3 | Elena | 27 | 1000 |
Пример использования синонимов колонок:
Индексы
Создание индексов
Индексы — это специальные поисковые таблицы (lookup tables), которые используются движком БД в целях более быстрого извлечения данных. Проще говоря, индекс — это указатель или ссылка на данные в таблице.
К индексам можно применять ограничение UNIQUE для того, чтобы обеспечить их уникальность.
Синтаксис создания индекса:
Синтаксис создания индекса для одной колонки:
Синтакис создания уникальных индексов (такие индексы используются не только для повышения производительности, но и для обеспечения согласованности данных):
Синтаксис создания индексов для нескольких колонок (композиционный индекс):
Решение о создании индексов для одной или нескольких колонок следует принимать на основе того, какие колонки будут часто использоваться в запросе WHERE в качестве условия для сортировки строк.
Для ограничений PRIMARY KEY и UNIQUE автоматически создаются неявные индексы.
Удаление индексов
Для удаления индексов используется инструкция DROP INDEX :
Несмотря на то, что индексы предназначены для повышения производительности БД, существуют ситуации, в которых их использования лучше избегать.
К таким ситуациям относится следующее:
Обновление таблицы
Команда ALTER TABLE используется для добавления, удаления и модификации колонок существующей таблицы. Также эта команда используется для добавления и удаления ограничений.
Добавляем в таблицу users новую колонку — пол пользователя:
Удаляем эту колонку:
Очистка таблицы
Команда TRUNCATE TABLE используется для очистки таблицы. Ее отличие от DROP TABLE состоит в том, что сохраняется структура таблицы ( DROP TABLE полностью удаляет таблицу и все ее данные).
Очищаем таблицу users :
Проверяем, что users пустая:
Представления
Представление (view) — это не что иное, как инструкция, записанная в БД под определенным названием. Другими словами, представление — это композиция таблицы в форме предварительно определенного запроса.
Представления могут содержать все или только некоторые строки таблицы. Представление может быть создано на основе одной или нескольких таблиц (это зависит от запроса для создания представления).
Представления — это виртутальные таблицы, позволяющие делать следующее:
Создание представления
Создаем представление для имен и возраста пользователей:
Получаем данные с помощью представления:
WITH CHECK OPTION
Если условие не удовлетворяется, выбрасывается исключение.
Обновление представления
Представление может быть обновлено при соблюдении следующих условий:
Пример обновления возраста пользователя с именем Igor в представлении:
Обратите внимание: обновление строки в представлении приводит к ее обновлению в базовой таблице.
С помощью команды DELETE можно удалять строки из представления.
Удаляем из представления пользователя, возраст которого составляет 26 лет:
Обратите внимание: удаление строки в представлении приводит к ее удалению в базовой таблице.
Удаление представления
Для удаления представления используется инструкция DROP VIEW :
Удаляем представление usersView :
HAVING
Транзакции
Транзакция — это единица работы или операции, выполняемой над БД. Это последовательность операций, выполняемых в логическом порядке. Эти операции могут запускаться как пользователем, так и какой-либо программой, функционирующей в БД.
Транзакция — это применение одного или более изменения к БД. Например, при создании/обновлении/удалении записи мы выполняем транзакцию. Важно контролировать выполнение таких операций в целях обеспечения согласованности данных и обработки возможных ошибок.
На практике, запросы, как правило, не отправляются в БД по одному, они группируются и выполняются как часть транзакции.
Свойства транзакции
Транзакции имеют 4 стандартных свойства (ACID):
Управление транзакцией
Для управления транзакцией используются следующие команды:
Удаляем пользователя, возраст которого составляет 26 лет, и отправляем изменения в БД:
Удаляем пользователя с именем Oleg и отменяем эту операцию:
Контрольные точки создаются с помощью такого синтаксиса:
Возврат к контрольной точке выполняется так:
Делаем выборку пользователей:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 31 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
| 4 | Oleg | 28 | Moscow | inactive |
Как видим, из таблицы был удален только пользователь с возрастом 26 лет.
Команда SET TRANSACTION используется для инициализации транзакции, т.е. начала ее выполнения. При этом, можно определять некоторые характеристики транзакции. Например, так можно определить уровень доступа транзакции (доступна только для чтения или для записи тоже):
Временные таблицы
Некоторые СУБД поддерживают так называемые временные таблицы (temporary tables). Такие таблицы позволяют хранить и обрабатывать промежуточные результаты с помощью таких же запросов, как и при работе с обычными таблицами.
Временные таблицы могут быть очень полезными при необходимости хранения временных данных. Одной из главных особенностей таких таблиц является то, что они удаляются по завершении текущей сессии. При запуске скрипта временная таблица удаляется после завершения выполнения этого скрипта. При доступе к БД с помощью клиентской программы, такая таблица будет удалена после закрытия этой программы.
Клонирование таблицы
Может возникнуть ситуация, когда потребуется получить точную копию существующей таблицы, а CREATE TABLE или SELECT окажется недостаточно в силу того, что мы хотим получить не только идентичную структуру, но также индексы, значения по умолчанию и т.д. копируемой таблицы.
Подзапросы
Подзапрос — это внутренний (вложенный) запрос другого запроса, встроенный (вставленный) с помощью WHERE или других инструкций.
Подзапрос используется для получения данных, которые будут использованы основным запросом в качестве условия для фильтрации возвращаемых записей.
Правила использования подзапросов:
| userId | userName | age | city | status |
|---|---|---|---|---|
| 1 | Igor | 30 | Moscow | active |
| 3 | Elena | 27 | Ekaterinburg | active |
Данные, возвращаемые подзапросом, могут использоваться и для удаления записей.
Последовательности
Последовательность — это набор целых чисел (1, 2, 3 и т.д.), генерируемых автоматически. Последовательности часто используются в БД, поскольку многие приложения нуждаются в уникальных значениях, используемых для идентификации строк.
Простейшим способом определения последовательности является использование AUTO_INCREMENT при создании таблицы:
Для того, чтобы заново пронумеровать строки с помощью автоматически генерируемых значений (например, при удалении большого количества строк), можно удалить колонку, содержащую такие значения и создать ее заново. Обратите внимание: такая таблица не должна быть частью объединения.



