Канонические ссылки и адреса страниц
Пример канонических URL адресов страниц
Характерный пример — страница сайта доступна по нескольким адресам:
Допустим, что предпочитаемым (каноническим) URL адресом является — /blog/seo/yandex. Значит в коде страниц:
необходимо отразить адрес канонической страницы:
Готовый код канонической ссылки:
Что такое канонические ссылки
Каноническая страница — это оригинальная страница или первоисточник. Каноническая ссылка (с атрибутом rel=canonical тега link) — не является строгой дерективой. Это значит, что указание страницы как канонической может как учитываться так и игнорироваться поисковыми роботами. Поисковые системы негативно относятся к дублированому контенту, будь это кража контента с другого сайта или дубликаты страниц на одном сайте.
Часто дублирование контента происходит из-за некорректной или плохо настроенной CMS. Организация канонических страниц как существенная часть seo оптимизации сайта позволяет избежать индексирования страниц-дублей. Кроме того, что это может снизить нагрузку на сайт, удаление ненужных страниц оптимизирует расход ресурсов, которые тратят поисковые системы на индексацию. Поисковые роботы будут быстрее находить новые страницы и другие изменения на сайте.
Как работают канонические ссылки
Правила, которые определяют корректное восприятие rel=canonical поисковыми системами:
Канонические ссылки (атрибут тега link rel canonical) позволяет указать какую именно страницу из группы похожих или одинаковых страниц нужно индексировать. Полезность данного инструмента сложно переоценить и глупо игнорировать. Ведь именно к правильному толкованию страниц сайта поисковыми системами, в значительной степени и сводится SEO сайта. Тем более, что канонические ссылки поддерживаются практически любой современной CMS вроде Joomla или WordPress.
Пишите в комментариях используете ли вы каннонические ссылки на своем сайте.
Делайте репосты статьи. Подписывайтесь на наш SEO блог.
Не дублируйте контент и ставьте правильные ссылки!
Все о rel canonical: как указывать атрибут правильно и зачем он нужен

Разбираемся, что нужно знать оптимизатору о работе с каноническими тегами. Материал для начинающих или тех, кто хочет освежить знания в памяти.
В статье:
Что такое rel canonical и для чего он нужен
Одинаковый контент на разных страницах — плохо, за это следуют санкции. Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Страницы могут быть не полностью одинаковыми. К примеру, на одной включен фильтр товаров по сезона, а на другой — сортировка по цене. Тем не менее, от включенных фильтров уникальными они не станут.
 Фильтр в каталоге сайта www.asos.com
Фильтр в каталоге сайта www.asos.com
В таких случаях нужно указывать, какой вариант страницы роботу считать основным, то есть каноническим, а какие дублями. Для этого придумали канонический тег — rel = «canonical», он решает проблему дублирования контента.
Каноническая страница — это основной URL. Атрибут rel = «canonical» добавляют на страницы-дубли и в нем указывают адрес канонической страницы, чтобы дать боту знать, какую страницу они повторяют.
Зачем указывать основную версию страницы?
Причины указывать canonical:
избежать санкций поисковиков за дублирование контента;
корректно передавать ссылочный вес на нужную версию сайта и страницы;
из контента, доступного по нескольким URL, выбрать страницу, которая будет получать все сигналы и показываться в выдаче;
Краткая информация о канонических URL из первых уст есть в справке Google и Яндекса.
Например, есть страница, доступная по трем адресам:
Допустим, мы хотим, чтобы страница site.ru/blog/category/tema ранжировалась в выдаче, получала весь положенный ей ссылочный вес и другие сигналы — считалась канонической.
Тогда эту страницу мы не трогаем, в коде страниц дублей site.ru/page?id=123 и site.ru/blog/tema указываем ее как каноническую. В коды дублей мы добавляем такую строчку:
Неканонические страницы не попадут в индекс?
Страницы, отмеченные как неканонические, все равно могут попасть в выдачу. Яндекс отмечает:
«Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом».
В Вебмастере у всех страниц появилась пометка «каноническая», «неканоническая» и «каноническая страница не указана». Вы можно посмотреть неканонические страницы, попавшие в выдачу, для этого откройте «Страницы в поиске» и ищите строчки с пометкой «Неканоническая».
 Неканоническая страница в выдаче
Неканоническая страница в выдаче
Google тоже заявляет, что система признает указанный канонический URL, но не всегда, поскольку тег canonical — рекомендация, а не приказ к действию. Если неканоническая покажется ему релевантнее, она и появится в выдаче.
Но если сеошник указывает этот атрибут, уменьшается риск, что Google сам определит основной не ту версию страницы.
Канонические страницы все равно появляются в поиске чаще и имеют приоритет при показе в выдаче, а ошибки с настройкой canonical могут привести к проблемам в индексировании страниц. Разберем все варианты, когда нужно использовать канонический тег.
Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL. Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Дублирование страниц
Дублирующиеся страницы с похожим содержанием, которые генерируются CMS. Они бывают на всех сайтах интернет-магазинов, где можно настраивать параметры выбора товара. Ссылки для навигации по каталогу, сортировка товаров, фильтрация, ссылки с UTM-метками для отслеживания, другие страницы с GET-параметрами в URL.
К примеру, если в каталоге есть несколько позиций одного дивана, отличающиеся только цветом обивки, можно выбрать самый популярный вариант и указать его каноническим. Все варианты диванов будут доступны пользователям, но ссылочный вес и другие сигналы будут идти на страницу с основным вариантом.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Переключение страниц в каталоге рождает дубли. Иногда для всех страниц пагинации указывают первую страницу в качестве канонической — это советуют не делать, потому что тогда проиндексируется только первая страница.
 Пагинация на сайте www.petshop.ru
Пагинация на сайте www.petshop.ru
Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https://site.ru/category1/page-2 нужно прописать канонический URL:
Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site.ru/category1/page2 нужно указать каноническую ссылку:
Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
Как настроить canonical правильно: 6 способов указать основной URL
Для использования канонического тега нужно выбрать среди дублей основной URL, вписать его в атрибут:
и добавить ко всем неосновным страницам.
Для добавления есть несколько способов:
С помощью плагина CMS
Большинство CMS имеют встроенную функцию или плагины, которые позволяют автоматизировать настройку канонического URL.
настроить canonical на WordPress можно с помощью плагина Yoast SEO;
в OpenCart в настройках товара можно задать SEO URL;
в Joomla версии от 3 и выше можно включить функцию SEF. Тогда в код технических страниц вида /index.php?option добавится атрибут rel = «canonical» с указанием основной страницы с ЧПУ.
Для примера подробнее рассмотрим WordPress как самую популярную CMS среди наших подписчиков.
Настройка canonical WordPress
Все просто: установите плагин Yoast SEO, чтобы канонические теги добавлялись автоматически.
Настроить теги для конкретной страницы можно в разделе «Дополнительно» («Advanced»), там нужно указать основной URL:
 Настройка канонического тега WordPress
Настройка канонического тега WordPress
Yoast SEO делает так, что если на странице появляется noindex или nofollow, тег canonical пропадает, чтобы не было проблем с представлением сайта в выдаче.
Если вы не используете CMS и не можете реализовать канонический тег плагинами, можно сделать все иначе.
Прописать между тегами любой HTML-страницы
Основной способ — прописать rel = «canonical» в секцию любой страницы-копии.
Например, если для страницы https://site.ru/*utm_content= канонической будет https://site.ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
В заголовке HTTP
При запросе дублирующего файла сервер должен отдавать ссылку на оригинальный файл:
К примеру, вы составили руководство, выложили его в блог и отдельно оформили в PDF-файл для скачивания, который разместили в подкаталоге http://site.ru/blog/*. HTTP-заголовок для этого руководства в PDF может выглядеть так:
С другими страницами так тоже можно.
В файле Sitemap
Поисковики по умолчанию думают обо всех ссылках в XML-файле как о канонических. У Google есть требование включать в Карту сайта только канонические адреса страниц. Но Карта не свод правил для поисковых ботов, а список рекомендаций, который поисковики могут проигнорировать.
Через 301 редирект
Отвести трафик и ссылочный вес от дублей к канонической страницы можно с помощью 301 редиректа. Этот способ можно использовать, если сайт, к примеру, доступен по нескольким адресам:
Можно выбрать в качестве основного https://site.ru/, а со всех остальных настроить перенаправление.
Дополнительный сигнал — ссылки
Представитель Google Джон Мюллер в этом видео перечислял все сигналы, которые поисковик использует для определения канонического адреса.
К примеру, между адресами HTTPS и HTTP Google выберет HTTPS, а еще он может предпочесть привлекательный с его точки зрения URL. В числе сигналов каноникализации числятся ссылки с одной страницы на другую. Если вы указали канонической одну страницу, а по совокупности факторов другая кажется поисковику более подходящей, он не будет вас слушать.
Неправильной настройкой можно навредить индексированию страниц. Разберем несколько типичных ошибок оптимизаторов.
Неправильно указан canonical: популярные ошибки настройки
Использование нескольких канонических ссылок для одной страницы
Для одной страницы нужно указать один канонический адрес. Если указано несколько, бот либо проигнорирует страницу вообще, либо примет к сведению первый указанный URL.
Проверяйте, как плагин CMS реализует canonical, иногда из-за неправильной настройки он может указывать несколько адресов.
Настройка разных канонических URL одной странице
Похожий пункт, но речь идет не о нескольких канонических адресах для одной страницы, а в о разных, указанных разными способами.
Настройка цепочки канонических URL
Бот не будет учитывать канонический адрес, если для страницы, которую вы указали основной, настроена какая-то своя основная страница. Например, для адреса site.ru/1 канонической ссылкой указана site.ru/2, а для нее указана site.ru/3.
Размещение rel = «canonical» не в секции head
Указание первой страницы пагинации как канонической
Если для всех страниц пагинации канонической указать первую, бот не проиндексирует остальные. Выше мы писали, как лучше сделать, есть три варианта:
сделать канонической страницу «Показать все», если она есть;
для каждой страницы поставить ее же URL в качестве канонической, если нет общей страницы.
Использование канонических URL вместо 301 редиректа
Тег canonical и 301 редирект кажутся похожими — перенаправляют бота на основную страницу. Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Выбор главной как канонической для всех страниц
Ошибкой будет указать главную страницу в качестве канонической для всего сайта. Боты могут проигнорировать все страницы, кроме главной.
Закрытие канонической страницы от индексирования
Если канонический URL закрыт от индексирования или по другой причине недоступен для поискового бота, он не сможет участвовать в формировании выдачи. В этом случае бот возьмет доступный неканонический URL.
Как проверить canonical
Проверить, для каких страниц вы настроили canonical и какие канонические страницы указали, можно с помощью сервиса Screaming Frog SEO Spider.
 Результаты проверки страниц краулером
Результаты проверки страниц краулером
Узнать, какую страницу Google считает основной для конкретного URL, можно через инструмент проверки URL.
Проверить, как поступил Яндекс, можно в Вебмастере: если вы верно указали каноническую страницу, дубли пропадут из поиска. Посмотрите страницу «Индексирование» — «Страницы в поиске». Если страницу исключили из результатов, она будет в блоке «Исключённые страницы».
 Проверка наличия дубля в выдаче
Проверка наличия дубля в выдаче
Рассказывайте, о каких необходимых вариантах использования canonical мы забыли, и какие еще ошибки настройки вы встречали в своей практике!
Канонические URL. Руководство по использованию атрибута rel = Canonical
Существует несколько причин образования дублей, например, CMS могут создавать дополнительные копии, где страница доступна по адресу с www и без. Особенно часто копии возникают в интернет-магазинах, где страницы товара отличаются только фотографией.
Канонический URL – это предпочитаемый адрес страницы, то есть, именно он будет индексироваться из группы схожих.
Канонический URL в борьбе с дублями.
Допустим, есть несколько адресов, ведущих на одну и ту же страницу:
Стоит отметить, что поисковые системы не гарантируют стопроцентного следования данному правилу. Однако, если вы не укажете каноническую страницу, то ПС может сделать это сама. В этом случае вы потеряете контроль над индексацией, так как поисковый робот выберет страницу рандомно и занесет в индекс.
Злоупотреблять атрибутом rel=canonical также не стоит. Встречались сайты, которые теряли позиции в результатах поиска после того, как разработчики ошибочно записывали в rel=canonical всех страниц сайта одинаковый url.
Как правильно использовать канонические урлы?
В чем разница между канонической ссылкой и 301-редирект?
Различие в принципе их действия. Атрибут rel=canonical показывает поисковой системе, какую страницу нужно индексировать и отображать в поиске. Остальные страницы не ранжируются, но на сайте пользователю видны. При использовании 301-редирект, вас автоматически перенаправляют на основную страницу. Если рассматривать с позиции передачи веса, то оба варианта будут передавать определенную часть веса канонической странице.
Одновременное использование rel=canonical и 301-редирект может оказаться плохой идеей. Мы говорим о тех случаях, когда вы указываете на страницу, как на каноническую, перенаправляя с нее, в свою очередь, на другую 301-редиректом. Скорее всего, поисковый робот посчитает это ошибкой. Возможно, передаваемый вес потеряется внутри этой цепи, что приведет к потере позиций в выдаче. Лучше не соединять канонические ссылки в цепь, а использовать только в пределах одного шага до основной страницы.
И еще несколько правил
Использование канонических URL не обязательное правило. Но если у вас есть дублированный контент, лучше решить эту проблему самостоятельно. Иначе поисковая система решит ее по-своему.
Канонические URL адреса страниц

Что такое канонические URL адреса?
В широком смысле слова, канонический означает «принятый за образец», «твердо установленный». То есть, канонический URL это, грубо говоря, основной адрес страницы.
Обычно, один материал имеет один URL адрес, к примеру www.example.ru/1.html. Но иногда одна и так же страница может быть доступна по нескольким адресам. К примеру: www.example.ru/1.html и www.example.ru/1/1.html. В таком случае, необходимо определить, какой из 2-х адресов является основным или каноническим.
Предположим, что www.example.ru/1.html был выбран в качестве основного URL. Тогда на странице с данным адресом (а так же, других страницах с копией контента) необходимо разместить следующий элемент:
Размещается он в шапке сайта, между тегов .
Внимание! Что бы снизить вероятность ошибки, внутри элемента link rel=»canonical» необходимо использовать абсолютные, а не относительные адреса. То есть, добавлять к ссылке домен.
Убедитесь, что в технической карте сайта sitemap.xml размещены именно канонические ссылки. Иначе это может привести к ошибкам индексирования.
Примеры канонических адресов
Предположим, что мы создали статью о продвижении Интернет-магазина одежды, для которой сделали красивый, понятный для человека URL.

Но статья осталась доступна по техническому адресу, который мы больше видеть не хотим.


Теперь адрес https://dh-agency.ru/prodvijenie-magazina-odejdy/ будет считаться основным.
Роль канонических адресов страниц в SEO
С точки зрения поисковой оптимизации, наличие одного основного URL адреса страницы просто необходимо. Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Нужно понимать, что краулер отводит ограниченное количество времени на индексацию сайта, поэтому многочисленные дубли страниц могут сильно ударить по эффективности его работы.
Правильно устанавливаем канонические URL адреса
Правильно установленный канонический адрес отвечает следующим требованиям:
Каноническая страница, указанная в элементе link rel=»canonical», обязательно должна существовать и быть доступна для пользователей;
Канонический адрес должен быть указан только для одного домена и поддомена. Грубо говоря, не должно быть ссылок на другие ресурсы;
Для страницы может быть указан один единственный канонический адрес;
Убедитесь, что на сайте отсутствуют рекурсии или «цепочки» канонических адресов. То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;
Уверены, что Ваши канонические адреса соответствуют всем вышеуказанным требованиям? Тогда можете считать их просто превосходными!
Понятие «каноническая ссылка»
Те, кто только начал окунаться в основы поисковой оптимизации, иногда разделяют понятия «канонический адрес» и «каноническая ссылка». На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
Нет никаких канонических и «главных ссылок ссылок для перелинковки».
301 редирект — замена rel=»canonical»?
Когда речь заходит о выборе между 301 редиректом и элементом link rel=»canonical», мы обычно советуем использовать именно переадресацию. Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Использование link rel=»canonical» актуально только тогда, когда сделать 301 редирект невозможно или проблематично.
Есть и еще один плюс link rel=»canonical» перед 301 редиректом — его простановку возможно сделать автоматической при создании страницы. К примеру, в WordPress эта функция уже реализована. То есть, заранее указав канонический адрес, Вы можете избавить себя от будущих проблем с индексацией.
Яндекс Вебмастер — статус «неканоническая»
Перейдя в этот раздел, Вы увидите все материалы, которые были по какой либо причине загружены в базу, но исключены из поиска.

Среди прочих причин исключения Вы можете увидеть статус «Неканоническая». Нажав на троеточие, отроется сообщение следующего вида:
«Страница проиндексирована по каноническому адресу https://dh-agency.ru/category/vnutrennyaya-optimizaciya/design/, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.»
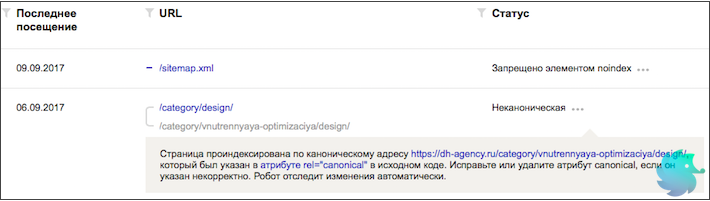
Что это значит?
Ничего страшного не произошло. Робот Яндекса проиндексировал страницу по первому (написанному синем шрифтом) URL, при этом на самой странице стоял элемент link rel=»canonical», в котором, в качестве канонического, был указан другой адрес (написанный серым шрифтом).

Пользуясь данной инструкцией, робот исключил неканонический URL.
Переживать, что материал был полностью исключен из поиска не стоит, он находится в выдаче, но по другому URL адресу.
Что с этим делать?
Если Вас не устраивает URL, который был выбран в качестве основного, необходимо поменять адрес в элементе link rel=»canonical» на предпочтительный. После изменения, страницу желательно отправить на переобход индексирующему роботу.

Так изменения будут загружены в базу в самое ближайшее время.



