Корреляционная матрица
При большом числе наблюдений, когда коэффициенты корреляции необходимо последовательно вычислять из нескольких рядов числовых данных, для удобства получаемые коэффициенты сводят в таблицы, называемые корреляционными матрицами.
Корреляционная матрица — это квадратная (или прямоугольная) таблица, в которой на пересечении соответствующих строки и столбца находится коэффициент корреляции между соответствующими параметрами.
В МS Ехсеl для вычисления корреляционных матриц используется процедура Корреляция. Процедура позволяет получить корреляционную матрицу, содержащую коэффициенты корреляции между различными параметрами.
Для реализации процедуры необходимо:
1) выполнить команду СервисàАнализ данных или выбрать пункт ленточного меню ДанныеàАнализ данных;
2) в появившемся списке Инструменты анализа выбрать строку Корреляция и нажать кнопку ОК;
3) в появившемся диалоговом окне указать Входной интервал, то есть ввести ссылку на ячейки, содержащие анализируемые данные. Для этого следует навести указатель мыши на левую верхнюю ячейку данных, нажать левую кнопку мыши и, не отпускал ее, протянуть указатель мыши к правой нижней ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши. Входной интервал должен содержать не менее двух столбцов;
4) в разделе Группировка переключатель установить в соответствии с введенными данными;
5) указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить флажок в левое поле Выходной интервал (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши на правое поле ввода Выходной интервал и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные (рис.18);
6) нажать кнопку ОК.
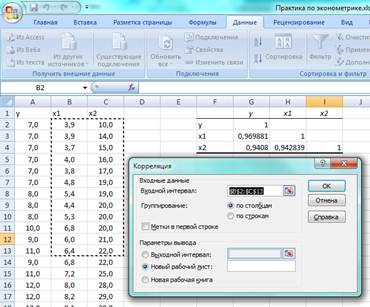
Рис. 18.Пример установки параметров корреляционного анализа
Результаты анализа, В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении каждых строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждый столбец во входном диапазоне полностью коррелирует с самим собой.
Интерпретация результатов. Рассматривается отдельно каждый коэффициент корреляции между соответствующими параметрами. Его числовое значение оценивается по эмпирическим правилам, изложенным в разделе «Коэффициент корреляции». Отметим, что хотя в результате будет получена треугольная матрица, корреляционная матрица симметрична, и коэффициенты корреляции rij= r ji.
Пример 6.14. Имеются ежемесячные данные наблюдений за состоянием погоды и посещаемостью музеев и парков.
| Число ясных дней | Количество посетителей музея | Количество посетителей парка |
Необходимо определить, существует ли взаимосвязь между состоянием погоды и посещаемостью музеев и парков.
Решение.Для выполнения корреляционного анализа введите в диапазон А1:GЗ исходные данные (рис. 19).
Затем в меню Данные выберите пункт Анализ данных и далее укажите строку Корреляция. В появившемся диалоговом окне укажите Входной интервал В1:GЗ.Укажите, что данные рассматриваются по строкам. Укажите выходной диапазон. Для этого поставьте флажок в левое поле Выходной интервал и в правое поле ввода Выходной интервал введите А4 (рис. 20). Нажмите кнопку ОК.
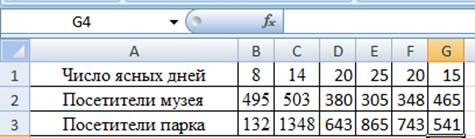
Рис. 19 Исходные данные
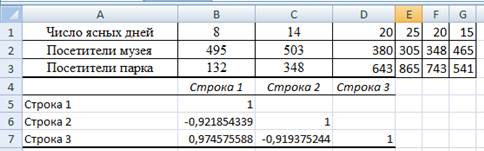
Рис. 20 Результаты вычисления корреляционной матрицы из примера 6.14
Результаты анализа. В выходном диапазоне получаем корреляционную матрицу (рис. 20).
Подразумевается, что в пустых клетках в правой верхней половине таблицы находятся те же коэффициенты корреляции, что и в нижней левой (симметрично расположенные относительно диагонали).
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Корреляции для начинающих
Апдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию!
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо, впрочем как и автор. Расчеты в Матлабе, подготовка данных в Экселе — так уж повелось в нашей местности 
Введение
Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.
Исходные данные
В качестве объекта исследования возьму данные о параметрах фигуры девушек месяца Плейбоя. Источник — www.wired.com/special_multimedia/2009/st_infoporn_1702, слегка облагородил и перевел из дюймов в сантиметры. Вспоминается анекдот про то, что 34 дюйма — это как два семнадцатидюймовых монитора. Также отделил записи с неполной информацией. При работе с реальными объектами их можно использовать, но сейчас они нам только мешают. Зато их можно использовать для проверки адекватности полученных результатов. Все данные у нас непрерывные, то есть грубо говоря типа float. Они приведены к целым числам только чтобы не загромождать экран. Есть способы работы и с дискретными данными — в нашем примере это например может быть цвет кожи или национальность, которые принимают одно из фиксированного набора значений. Это больше имеет отношение к методам классификации и принятия решений, что тянет еще на один мануал. Data.xls В файле два листа. На первом собственно данные, на втором — отсеянные неполные данные и набор для проверки нашей модели.
Обозначения
W — вес реальный
W_p — вес, предсказанный нашей моделью
S — бюст
T — талия
B — бедра
L — рост
E — ошибка модели
Как оценить качество модели?
Задача нашего упражнения — получить некую модель, которая описывает какой-либо объект. Способ получения и принцип работы конкретной модели нас пока не волнует. Это просто функция f(S, T, B, L), которая выдает вес девушки. Как понять, какая функция хорошая и качественная, а какая не очень? Для этого используется так называемая fitness function. Самая классическая и часто используемая — это сумма квадратов разницы предсказанного и реального значения. В нашем случае это будет сумма (W_p — W)^2 для всех точек. Собственно, отсюда и пошло название «метод наименьших квадратов». Критерий не лучший и не единственный, но вполне приемлемый как метод по умолчанию. Его особенность в том, что он чувствителен по отношению к выбросам и тем самым, считает такие модели менее качественными. Есть еще всякие методы наименьших модулей итд, но сейчас нам это пока не надо.
Простая линейная регрессия
Самый простой случай. У нас одна переменная-предиктор и одна зависимая переменная. В нашем случае это может быть например рост и вес. Нам надо построить уравнение W_p = a*L+b, т.е. найти коэффициенты a и b. Если мы проведем этот расчет для каждого образца, то W_p будет максимально совпадать с W для того же образца. То есть у нас для каждой девушки будет такое уравнение:
W_p_i = a*L_i+b
E_i = (W_p-W)^2
Общая ошибка в таком случае составит sum(E_i). В результате, для оптимальных значений a и b sum(E_i) будет минимальным. Как же найти уравнение?
Матлаб
Графичек

Мда, негусто. Это график W_p(W). Формула на графике показывает связь W_p и W. В идеале там будет W_p = W*1 + 0. Вылезла дискретизация исходных данных — облако точек клетчатое. Коэффициент корреляции ни в дугу — данные слабо коррелированы между собой, т.е. наша модель плохо описывает связь веса и роста. По графику это видно как точки, расположенные в форме слабо вытянутого вдоль прямой облака. Хорошая модель даст облако растянутое в узкую полосу, еще более плохая — просто хаотичный набор точек или круглое облако. Модель необходимо дополнить. Про коэффициент корреляции стоит рассказать отдельно, потому что его часто используют абсолютно неправильно.
Расчет в матричном виде
Мультилинейная регрессия
Попытка номер два
А так получше, но все равно не очень. Как видим, клетчатость осталась только по горизонтали. Никуда не денешься, исходные веса были целыми числами в фунтах. То есть после конверсии в килограммы они ложатся на сетку с шагом около 0.5. Итого финальный вид нашей модели:
W_p = 0.2271*S + 0.1851*T + 0.3125*B + 0.3949*L — 72.9132
Объемы в сантиметрах, вес в кг. Поскольку у нас все величины кроме роста в одних единицах измерения и примерно одного порядка по величине (кроме талии), то мы можем оценить их вклады в общий вес. Рассуждения примерно в таком духе: коэффициент при талии самый маленький, равно как и сами величины в сантиметрах. Значит, вклад этого параметра в вес минимален. У бюста и особенно у бедер он больше, т.е. сантиметр на талии дает меньшую прибавку к массе, чем на груди. А больше всего на вес влияет объем задницы. Впрочем, это знает любой интересующийся вопросом мужчина. То есть как минимум, наша модель реальной жизни не противоречит.
Валидация модели
Название громкое, но попробуем получить хотя бы ориентировочные веса тех девушек, для которых есть полный набор размеров, но нет веса. Их 7: с мая по июнь 1956 года, июль 1957, март 1987, август 1988. Находим предсказанные по модели веса: W_p=X*repr
Что ж, по крайней мере в текстовом виде выглядит правдоподобно. А насколько это соответствует реальности — решать вам
Применимость
Если вкратце — полученная модель годится для объектов, подобных нашему набору данных. То есть по полученным корреляциям не стоит считать параметры фигур женщин с весом 80+, возрастом, сильно отличающимся от среднего по больнице итд. В реальных применениях можно считать, что модель пригодна, если параметры изучаемого объекта не слишком отличаются от средних значений этих же параметров для исходного набора данных. Могут возникнуть (и возникнут) проблемы, если у нас предикторы сильно коррелированы между собой. То есть, например это рост и длина ног. Тогда коэффициенты для соответствующих величин в уравнении регрессии будут определены с малой точностью. В таком случае надо выбросить один из параметров, или воспользоваться методом главных компонент для снижения количества предикторов. Если у нас малая выборка и/или много предикторов, то мы рискуем попасть в переопределенность модели. То есть если мы возьмем 604 параметра для нашей выборки (а в таблице всего 604 девушки), то сможем аналитически получить уравнение с 604+1 слагаемым, которое абсолютно точно опишет то, что мы в него забросили. Но предсказательная сила у него будет весьма невелика. Наконец, далеко не все объекты можно описать мультилинейной зависимостью. Бывают и логарифмические, и степенные, и всякие сложные. Их поиск — это уже совсем другой вопрос.
Корреляционный анализ или Почему существуют странные корреляции
На данный опус меня навела публикация «Деньги, товар и немного статистики. Часть вторая», в которой автор исследовал зависимости между ценами на различные товары. Несколько смутило то, что несмотря на мастерское обращение с MatLab’ом, автор ни разу не упомянул об уровне значимости полученных корреляций. Ведь, связь между двумя величинами может и существовать, но если она статистически не значима, говорить о ней мы можем лишь в контексте рассуждений и домыслов.
Пощупать данные «руками» долго не получалось, но вот выдался свободный час, и я, вооружившись R, двинулся в путь.
Немаловажный момент — распределение нормированных цен на все товары отличалось от нормального (р-значение для критерия Шапиро-Уилка значительно меньше 0.001), что неумолимо приводит нас к тому, что использование относительно «доброго» для поиска взаимосвязей коэффициента корреляции Пирсона не представляется возможным. К счастью, существует его непараметрический аналог — тест Спирмена.
Итак, корреляционная матрица получена. Взглянем на нее:

Окей, корреляции имеют место быть, хотя значения rho уже поменьше. Найдем наиболее высокие уровни и проверим их значимость:
Для экономии места скажу, что для всех обнаруженных корреляционных взаимосвязей р-значение было меньше 0.0001, что говорит о статистически значимом явлении. Корреляционная матрица представлена ниже:
1 gold oil 0.2451402
2 iron gold 0.2503873
3 logs iron 0.2446200
4 maize logs 0.2547667
5 beef maize 0.2398418
6 chicken beef 0.2385301
7 gas chicken 0.2481030
8 liquid_gas gas 0.2544752
9 tea liquid_gas 0.2367907
10 tobacco tea 0.2416664
11 wheat tobacco 0.2553935
12 sugar wheat 0.2505641
13 soy sugar 0.2440920
14 silver soy 0.2589974
15 rice silver 0.2403048
16 platinum rice 0.2418105
17 cotton platinum 0.2343923
18 copper cotton 0.2498545
19 coffee copper 0.2321891
20 coal coffee 0.2482226
21 aluminum coal 0.2423581
Как видим, полученные rho не превышают 0.3, что указывает на слабую силу связи (согласно шкале Чеддока). Фактически, оперировать такими данными можно, но всегда нужно понимать, что колебания цен одного товара будет не боле чем на 10% сказываться на цене своего «партнера» по корреляции.
Хотелось бы отметить, что похожая линия рассуждений должна использоваться при анализе других странных корреляций. Цифры могут играть с нами злые шутки.
Спасибо jatx за то, что дал повод поиграть с цифрами!
Корреляционная матрица для чего нужна
Если две величины связаны между собой, то между ними есть корреляция. Виды корреляционной связи показаны в таблице 3.9.
Для выяснения вопроса о наличии связи между двумя величинами X и Y необходимо определить, существует ли соответствие между большими и малыми значениями X и соответствующими значениями Y или такой связи не обнаруживается. Значение каждого элемента Xi и Yi определяется величиной и знаком отклонения от среднего арифметического 11 :
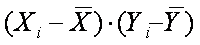
Если большие значения Xi соответствуют большим значениям Yi, то это произведение будет большим и положительным, так как
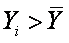 и
и 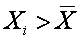
То же самое будет наблюдаться и, когда малые значения Xi будут соответствовать малым Yi, поскольку произведение отрицательных чисел будет положительным.
Если же большие значения Xi соответствуют малым значениям Yi, то это произведение будет большим и отрицательным, что будет свидетельствовать об обратной зависимости между этими величинами.
В тех случаях, когда нет систематического соответствия больших значений Xi большим или малым Yi, то знак произведения будет положительным или отрицательным для разных пар Xi и Yi. Тогда сумма
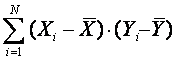
Для того, чтобы эта сумма не зависела от количества значений X и Y, ее следует поделить ее на N-1. Полученная величина sXY называется ковариацией X и Y и является мерой их связи:
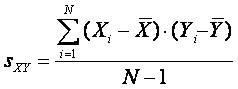
Для исключения влияния стандартных отклонений на величину связи, следует поделить ковариацию sXY на стандартные отклонения sX и sY:
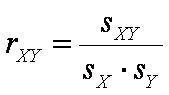
Полученная мера связи между X и Y называется коэффициентом корреляции Пирсона. Обозначение r происходит от слова регрессия. Подставив соответствующие выражения, получим формулу для коэффициента корреляции Пирсона rXY 11
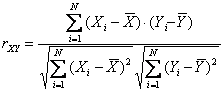
Для вычислений более удобна следующая формула

Следует отметить, что в случае нелинейной связи между X и Y коэффициент корреляции может оказаться близким к нулю, даже если связь очень сильная.
Таблица 3.7.1. Типы корреляционной связи
(Гласс Дж., Стэнли Дж., 1976).

Для решения вопроса о наличии связи между заданиями теста, надо, используя данные по столбцам из бинарной матрицы, рассчитать коэффициенты корреляции Пирсона для каждой пары заданий. Для расчетов используются различные статистические программы (SPSS, STATISTICA и др.). В простейшем случае можно использовать табличный процессор Excel с вызовом функции «ПИРСОН».
pm – доля верных ответов для задания с номером m;
qm – доля неверных ответов для задания с номером m;
pk – доля верных ответов для задания k;
qk – доля неверных ответов для задания с номером k;
pmk – доля верных ответов для задания с номером m и k.
Коэффициент корреляции Пирсона, для дихотомических данных называется коэффициентом «фи». Коэффициент φmk, описывающий связь между заданиями с номерами m и k записывается следующим образом 11
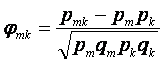
Отметим, что коэффициент «фи» и коэффициент корреляции Пирсона дают в результате одно и то же значение, поскольку обе формулы эквивалентны. Рассмотрим пример вычисления коэффициента корреляции между 2-м и 5-м заданиями. Из таблицы 3.2.5 имеем: p2=0.7, q2=0.3, p5=0.5, q5=0.5. Для определения p25 надо подсчитать количество верных ответов на оба задания одновременно. Видно, что испытуемые с номерами 1-5 успешно справились с обоими заданиями (5 верных ответов). Испытуемые 6 и 7 правильно ответили на 2-е задание, но неправильно на 5-е (нет одновременно верных ответов). Испытуемые 8 и 9 не справились и со 2-м и с 5-м заданиями. Таким образом, p25 =5/10 = 0,5.
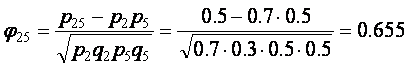
Результаты расчетов для всех заданий приведены в корреляционной матрице (таблица 3.7.2). Корреляционная матрица представляет собой квадратную матрицу размерности MxM, где M – количество заданий, симметричную относительно главной диагонали. В нашем примере матрица имеет 8 строк и столько же столбцов. Коэффициент корреляции Пирсона, скажем, между 2-м и 5-м заданиями находится на пересечении 2-й строки и 5-го столбца (0,655).
В самом последнем столбце располагается коэффициент корреляции каждого задания с тестовым баллом испытуемого (индивидуальным баллом) – rpb – точечный бисериальный коэффициент корреляции.
ТАБЛИЦА 3.7.2. Корреляционная матрица тестовых заданий.
Представление данных корреляционного анализа
Традиционно данные корреляционного анализа представляются в виде корреляционной матрицы.
Корреляционная матрица – это квадратная таблица, заголовками строк и столбцов которой являются обрабатываемые переменные.
На пересечении строк и столбцов выводится коэффициент корреляции для соответствующей пары признаков.
Корреляционная матрица обладает следующими свойствами (рис.1):
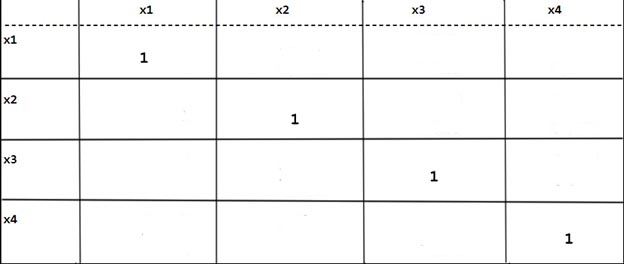
В пакете STATGRAPHICS корреляционная матрица выглядит следующим образом (рис.2), на главной диагонали цифра «1» не стоит.
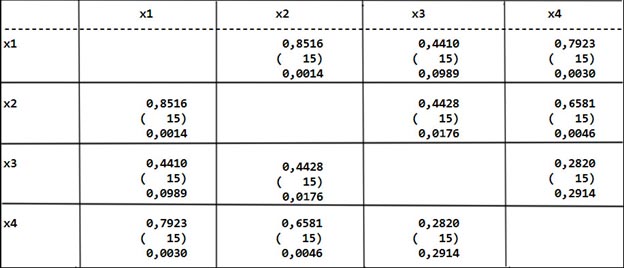
На пересечении пары переменных в ячейке матрицы записываются три значения:
О представлении данных корреляционного анализа можно прочесть в книге «Компьютерная обработка данных экспериментальных исследований»
Для представления данных корреляционного анализа используется несколько способов.
ПЕРВЫЙ СПОСОБ
Значимость коэффициентов корреляции определяется на основе приведенного в заголовке таблицы критического значения коэффициента корреляции (rкрит) при определенном уровне значимости α. Также в заголовке таблицы приведен объем выборки (n). Для читающего таблицу с таким представлением информации ясно, что все коэффициенты корреляции, значения которых больше критического являются значимыми. Так корреляционная матрица представлена в книге Ан. Шалманова и Я. Ланки «Биомеханика толкания ядра».
Таблица 1 — Корреляционная матрица результатов в толкании ядра и скоростно-силовых тестах (n = 32, rкрит= 0,349, α = 0,05)
| № | Упражнение | 1 | 2 | 3 | 4 | 5 | 6 | ||||||||||||||||||||||||||||||
| 1 | Толкание ядра с разгона | 1 | 0,97 | 0,84 | 0,83 | 0,73 | 0,73 | ||||||||||||||||||||||||||||||
| 2 | Толкание ядра с места | 1 | 0,84 | 0,82 | 0,74 | 0,76 | |||||||||||||||||||||||||||||||
| 3 | Бросок ядра назад | 1 | 0,85 | 0,71 | 0,66 | ||||||||||||||||||||||||||||||||
| 4 | Бросок ядра вперед | 1 | 0,66 | 0,62 | |||||||||||||||||||||||||||||||||
| 5 | Приседание со штангой | 1 | 0,58 | ||||||||||||||||||||||||||||||||||
| 6 | Жим штанги лежа |
| № | Тест | 1 | 2 | 3 | 4 | 5 |
| 1 | Темп, гр/мин | 1 | — | — | — | — |
| 2 | Время проплывания 25 м, с | 1 | 0,911 | 0,679 | 0,859 | |
| 3 | Время проплывания 50 м, с | 0,679 * | 0,859 *** | |||
| 3 | Время проплывания 50 м, с | 1 | 0,861 *** | 0,969 *** | ||
| 4 | Время проплывания 100 м, с | 1 | 0,865 *** | |||
| 5 | Время проплывания 200 м, с | 1 |
Примечание: * – коэффициент корреляции достоверен, р



