Выполняю установку, настройку, сопровождение серверов. Для уточнения деталей используйте форму обратной связи
Данная статья является в некотором смысле вольным переводом статьи http://blogs.oracle.com/vreality/entry/storage_virtualization_with_comstar + мои дополнения.
1) Введение.
Сам по себе протокол FC инкапсулирует команды iSCSI, но в качестве среды передачи данных использует оптические каналы. В связи с этим, увеличивается стоимость (нужны соответственно оптические коммутаторы и прочее оборудование), но зато увеличивается и надёжность. Этот протокол, в отличии от iSCSI, лишён потери пакетов (так как не использует TCP/IP).
В FC существуют 2 типа портов: initiator и target. Initiator — это по сути клиент, а target — порт через который доступно хранилище.
Список портов можно посмотреть через команду:
Если порт присутствует, но не подключён — мы об этом узнаем.
По сути данная команда показывает только порты initiator’ы. Что бы посмотреть все доступные порты, можно использовать такой метод:
Здесь мы видим присутствие 2-х портов в режиме initiator (используется драйвер qlc).
2) Установка поддержки FC
В Solaris 11, в отличии от 10 очень много сервисов (samba, iscsi, fc, …) собраны в единый пакет storage-server. Отдельно поставить какой-нибудь компонент никак нельзя. Ставим его:
#pkg install storage-server
Для управления шарами используется сервис STMF, который по умолчанию отключён.
# svcs stmf
disabled 15:58:17 svc:/system/stmf:default
# svcadm enable stmf
# svcs stmf
online 15:59:53 svc:/system/stmf:default
3) Создание target’a.
Создаём пул, на котором будем создавать ФС, которая и будет выступать в последствии LUN’ом (логической единицей для хранения данных). Хочу обратить внимание, что zfs нужно создавать обязательно с указанием объёма, иначе LUN не создастся:
и проверим создание
Следующим этапом сделаем наш LUN видимым для всех initiator’ов в сети:
# stmfadm add-view 600144f07bb2ca0000004a4c5eda0001
4) Информация о портах
Посмотрим информацию о портах:
Детальная информация о порте:
А так можно посмотреть информацию об устройствах (порты c12, c13 — FC-порты)
5) Изменения режима работы порта.
Что бы перевести порт в режим, например, target’a делаем следующее:
где путь берётся из вывода luxadm и /pci@0,0/pci1002,5a1f@b/pci1077,138@0,1/fp@0,0 — путь относительно каталога /devices. Ошибка значит лишь то, что в данный момент оно не может выгрузить драйвер — он будет выгружен при ребуте.
После изменения выполним
Далее, заходим в mdb и смотрим:
Как видим изменения прошли. Так же можно посмотреть инфу и через fcinfo:
Так же можно посмотреть список target’ов:
После того, как вы настроили target’ы, переходим к initiator’ам.
Что бы заново пересканировать все доступные target’ы, выполним команду:
и теперь новые диски станут доступными. Что посмотреть изменения, запустим команду format:
# format
Searching for disks.
AVAILABLE DISK SELECTIONS:
0. c1t0d0
/pci@7c0/pci@0/pci@1/pci@0,2/LSILogic,sas@2/sd@0,0
1. c1t2d0
/pci@7c0/pci@0/pci@1/pci@0,2/LSILogic,sas@2/sd@2,0
2. c1t3d0
/pci@7c0/pci@0/pci@1/pci@0,2/LSILogic,sas@2/sd@3,0
3. c2t210000E08B91FACDd0
/pci@7c0/pci@0/pci@9/SUNW,qlc@0/fp@0,0/ssd@w210000e08b91facd,0
Specify disk (enter its number):
Как можно заметить, у нас появился новый диск SUN-COMSTAR. Далее с ним можно работать как с обычным, то есть создавать пул, ФС, …
Примечание.
По не выясненным причинам во время загрузки ОС FC-порт долго поднимался, и в итоге пул был недоступен и из-за этого ОС грузилась достаточно долго, но пул всё равно оставался недоступным. В итоге пришлось отказаться от FC.
7) Multipathing
При настройке разного рода FC/iSCSI очень желательно настроить и multipathing.
Очень неплохой tutorial по multipathing описан здесь
How to check Fibre Channel HBAs in Linux
Fibre Channel (FC) Host Bus Adapters(HBA) are interface cards that connects the host system to a fibre channel network or devices. The two major manufacturers of FC HBAs are QLogic and Emulex and the drivers for many HBAs are distributed in-box with the Operating Systems. If the drivers are not available on your Linux version, you need to install them manually and load the modules in kernel
Here is a step by step guide to verify that your FC HBAs installed and configured correctly.
Step-1: Determine the Manufacturer and Model of the HBAs.
Run the lspci command to list all PCI cards detected on the system.
The above output shows the system bus has detected two QLogic HBAs.
Step-2: Get the Vendor and Device IDs for the HBAs installed.
These can be obtained from the file /usr/share/hwdata/pci.ids
Step-3: Check if the driver modules are installed.
This can be done by searching the list of available modules. (Replace 2.6.18-308.el5PAE with your kernel version in the command below)
The above output shows that this HBA is supported by the module qla2xxx
Step-4: Check if the drivers for these HBAs are loaded in the kernel.
The lsmod command will list the currently loaded kernel modules
The output shows the module qla2xxx is loaded by the kernel. If you don’t see any output for lsmod command then you can load the module using modprobe command
Step-5: Getting detailed information
You can find detailed information about the fibre channel adapters in the location /sys/class/fc_host/
The directories host3 and host4 in the example above contains information specific to each adapter like node name (WWN), port name (WWN), type, speed,state etc.,
An easier way to get this information is to use the systool command.

Related Articles
Post a comment
Comments
unfortunately systools is no more available in most distros
You’re using the wrong distro then, it’s in rhel/centos 7.
Hello, How we can tell, that we have 2 x 2-port hba and not 4 x 1 hba port hba? Thanks10:00.0 Fibre Channel: Emulex Corporation Lancer-X: LightPulse Fibre Channel Host Adapter (rev 30) 10:00.1 Fibre Channel: Emulex Corporation Lancer-X: LightPulse Fibre Channel Host Adapter (rev 30) 15:00.0 Fibre Channel: Emulex Corporation Lancer-X: LightPulse Fibre Channel Host Adapter (rev 30) 15:00.1 Fibre Ch
Nice information and very simple to understand.
Good link, Had my hba configured, But have an other problem where hba is showing down.
База знаний wiki
Продукты
Статьи
Содержание
fc подключение к схд сервера под linux
Применимость: Linux, выделенный сервер
Слова для поиска: storage, Huawei OceanStor
Задача:
Как подключиться к LUN выделенному на системе хранения
Решение:
Обновите систему и перезагрузите сервер с новым ядром
Обновление драйвера QLE2562
Ядро уже содержит драйвер для QLE2562, но вы можете использовать самый свежий драйвер с сайта производителя. Скачайте архив с драйвером
Установка компиляторов и прочих пакетов:
Распаковать архив с драйвером и выполнить установку:
Проверить версию установленного драйвера:
Получение параметров HBA
Найти HBA карты на вашем сервере:
Есть другие способы чтобы получить информацию о HBA, но удобнее использовать systool (пакет sysfsutils).
Сообщите эти значения администратору для настройки параметров доступа к вашему LUN
Определить статус портов:
Если статус Online и настроен доступ на СХД, то можно перезагрузить модуль адаптера и попытаться увидеть ваш LUN
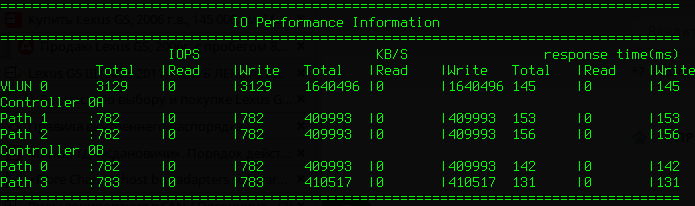
В этом примере мне выделен один LUN на 200GB, но я вижу 8 штук. Причина в том, что этот LUN виден по 8-ми путям. 2 порта на моем сервере и группа из 4-х портов на СХД образуют 8 возможных путей прохождения данных.
Это необходимо для распределения нагрузки и отказоустойчивости.
Для использования всех нужно использовать либо службу Multipath или Huawei OceanStor UltraPath
Многопутевой ввод-вывод (Multipath I/O)
Использовать много-путевой доступ необходимо даже в том случае если на вашем сервере используется 1 порт.
Иначе, например, в случае обновления прошивки на одном из контроллеров СХД произойдет временное отключение вашего сервера от СХД и данные на вашем LUN могу быть повреждены.
Многопутевой ввод-вывод (Multipath I/O) — технология подключения узлов сети хранения данных с использованием нескольких маршрутов. В случае отказа одного из контроллеров, операционная система будет использовать другой для доступа к устройству. Это повышает отказоустойчивость системы и позволяет распределять нагрузку.
Multipath устройства объединяются в одно устройство с помощью специализированного программного обеспечения в новое устройство. Multipath обеспечивает выбор пути и переключение на новый маршрут при отказе текущего. Это происходит невидимо для программ и процессов использующих это устройство. Кроме того Multipath способен распределять передачу данных по разным путям посредством различных алгоритмов, например:
Преимущества Huawei UltraPath
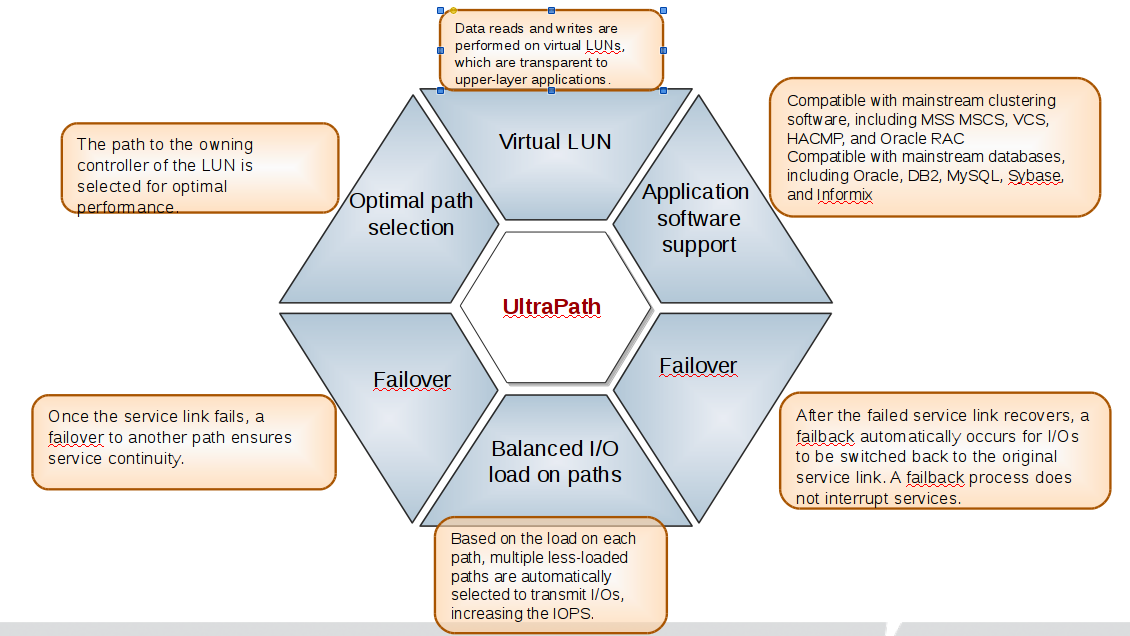
Установка OceanStor UltraPath
Запросить у службы поддержки ссылку на пакет OceanStor UltraPath соответствующий версии вашей ОС.
В ходе установки вам будет предложено выбрать опции:
Если для подключения к системе хранения используются HBA адаптеры HCA, QLogic или Emulex, мы рекомендуем установить значение N.
Установите следующие параметры драйвера HBA адаптера:
Например для QLogic (qla2xxx) в файле /etc/modprobe.d/nxupmodules.conf следует добавить строки, если их там нет:
Для программного адаптера Linux-iscsi (Red Hat AS4) в файле /etc/iscsi.conf должны быть параметры:
Для программного адаптера open-iscsi (RHEL-7, Centos) в файле /etc/iscsi/iscsid.conf должны быть параметры:
Убедитесь, что UltraPath работает
lsscsi | grep updisk [8:0:0:1] disk up updisk 4303 /dev/sdc
В данном случае виртуальный диск созданный UltraPath имеет имя /dev/sdc
В дальнейшем вы можете использовать его для всех нужд
Создать файловую систему XFS:
Настройка UltraPath
Для управления параметрами используется утилита upadmin
Конфигурация по умолчанию после установки:
Здесь стоит изменить параметр Working Mode чтобы данные одновременно передавались по всем путям
Контроль I/O по путям для LUN с идентификатором 0:
Пересканировать SCSI
Если у вас изменился список scsi устройств (добавили LUN), то система не увидит их сама В дистрибутивах основанных на Red Hat есть скрипт:
После отрабатывания скрипта проверьте вывод команды:
Настройка fiber channel linux
а) Общая информация по настройке FC-target
FC использует свою адресацию, поэтому для указания, с таким устройством работать, используется WWN (World Wide Name, параметр node_name (есть ещё port_name (WWP), но они отличаются, хотя и похожи)):
Если необходимо узнать WWN адаптера, доступной по Fibre Channel, то информацию можно найти в каталоге:
б) HBA Emulex
в) HBA QLogic
По умолчанию FC HBA стартует в режиме инициатора (initiator mode), поэтому надо карту при инициализации перевести в режим цели (target mode).
Для этого есть два варианта:
1) дописать в параметры ядра ещё один (и перегрузиться, конечно):
2) создать файл /etc/modprobe.d/qla2xxx.conf с такой строкой:
Проверка, что карта в нужном режиме:
И запустим службу восстановления конфигурации (Restore LIO kernel target configuration):
Если после запуска мы будет находиться не в корне (например, /qla2xxx), то выйдем на него:
Посмотрим исходное состояние:
Создадим объект хранилища для нашей будущей Цели (target):
Привязываем ранее созданное блочное устройство к Цели:
Смотрим результат наших операций:
Если всё устраивает, сохраняем конфигурацию (специально, если отключено автоматическое сохранение (по умолчанию)):
Указывается, что текущая конфигурация сохранена в /etc/target/saveconfig.json, а в /etc/target/backup находятся 10 предыдущих вариантов.
Если возникает желание/необходимость что-то удалить, переходим в нужную ветку дерева и удаляем, например, LUN:
Теперь посмотрим, доступен ли наш LUN на целевой системе, Инициаторе, пересканировав доступные LUN:
Чтобы добавить одно заданное устройство, выполним:
Чтобы удалить заданное устройство, выполним:
где — это хост, шина, целевой номер устройства и логический номер (host, bus, target, LUN) соответственно. Соответствующие устройству номера можно найти в каталоге /sys (только для ядер версии 2.6), файле /proc/scsi/scsi или выводе команды dmesg.
Удалить (отключить) LUN:
2. Infiniband
а) Общая информация по настройке
б) HCA: QLogic
в) HCA: Mellanox
3. iSCSI
4. Программный RAID
а) Создание RAID-массива
Для работы с программным RAID в Linux используется утилита mdadm. Создание с её помощью массива RAID1:
Сканирование системы на наличие массивов и вывода информации по ним (в форме для добавления в файл конфигураций /etc/mdadm/mdadm.conf):
б) Мониторинг состояния массива
Состояние RAID-массива отслеживается через файл /proc/mdstat:
Информация о конкретном дисковом разделе:
Для постоянной периодической проверки эту команду надо внести в файл, например, mdRAIDmon, размещённый в папке /etc/cron.haurly/.
Или, для пятиминутной проверки внести в файл /etc/crontab следующую строку:
Проверки работы системы оповещения:
в) Работа с разделами на RAID-массиве
Удаление LVM и RAID, где он размещён:
Иногда после данных информация о томах всё ещё отображается, поэтому переподключить массив или перезагрузить сиситему.
г) Поддержка bitmap
Включение поддержки bitmap с хранением:
Просмотр включенных bitmap:
Отключение на RAID-массиве использование bitmap:
Параметр bitmap в свойствах массива означает добавление дополнительной информации для восстановления RAID в случае сбоев. Сборка массива при замене жёсткого диска будет происходить быстрее, но общая производительность массива снизится примерно на 5% в случае размещения bitmap на том же диске, что и RAID или в самом RAID-массиве (по умолчанию).
е) Очистка дисков от метаданных RAID
Отмонтируем все разделы, размещённые на удаляемом RAID и остановим этот массив:
Стираем суперблок, хранящий информацию о массиве, на всех дисках, входящих в удаляемый массив:
Если не получилось, то делаем прямым затиранием:
Выключаем систему, отключаем девственно чистые диски. :\
5. Работа с LVM
а) Отключение/подключение диска с LVM
Это требуется, например, после подключения диска с LVM к системе через, например, USB конвертер. Если отключать диск без некоторых дополнительных действий, то в системе останутся «зависшими» подключения, что может вызвать некоторые проблемы.
Для отключения надо:
1) отмонтировать все разделы на этом диске;
2) выполнить команду:
3) удаляем блочное устройство (в современных системах происходит автоматически, но вдруг понадобится) /dev/sdf:
Теперь можно монтировать.
б) Создание томов LVM
Посредством утилиты fdisk создаём (описано в предыдущем пункте) на новом диске таблицу разделов и раздел на нём.
Создание новых томов (физического, группы и логического) на дополнительном диске /dev/sdb:
Добавляем новую запись к файл /etc/fstab и на этом заканчивается настройка.
в) Восстановление удалённых томов
г) Изменение размеров томов
Создаём новый физический том на созданном разделе:
Смотрим, на какой группе томов расположен корневой раздел /dev/sda2:
Добавляем к этой группе созданный нами раздел /dev/sda3:
Смотрим путь, по которому доступен целевой логический том:
Выделяем целевому тому необходимое место:
В качестве альтернативного пути может быть использован любой:
1) через mapper: /dev/mapper/lvmpart-root;
2) через любой путь в каталоге /dev/disk/.
Теперь остаётся изменить размер файловой системы, размещённой на целевом логическом томе. Это производится для каждой файловой системы по своему:
Для увеличения размера целевой файловой системы всё сделано.
При необходимости уменьшить размер всё производится в обратном порядке, но действия производятся только на размонтированных файловых системах. Т.е., в случае с корневым разделом надо предварительно загрузиться с LiveCD с поддержкой LVM2. ВАЖНО!: операция уменьшения невозможна для XFS.
Теперь вносим изменения в группы томов и физические тома.
д) Дополнительная информация
6. Некоторые особенности настройки FreeNAS 10
Смена пароля root через CLI:
Так же надо назначить IP адрес:
В 10 версии полностью переработаны интерфейсы: и графический (GUI) и консольный (CLI).
Если используется Fibre Channel карта для работы с СХД на базе FreeNAS, то для создания и презентации соответствующего LUN надо использовать ctladm. По сути: в интерфейсе WebGUI настраивается iSCSI, а для работы активировать FC интерфейс:
Хорошо поддерживаются FC-карты QLogix (устройство isp X ).
размещено: 2012-08-03,
последнее обновление: 2019-09-03,
автор: Fomalhaut
Alex, 2018-11-12 в 16:01:24
Этот информационный блок появился по той простой причине, что многие считают нормальным, брать чужую информацию не уведомляя автора (что не так страшно), и не оставляя линк на оригинал и автора — что более существенно. Я не против распространения информации — только за. Только условие простое — извольте подписывать автора, и оставлять линк на оригинальную страницу в виде прямой, активной, нескриптовой, незакрытой от индексирования, и не запрещенной для следования роботов ссылки.
Если соизволите поставить автора в известность — то вообще почёт вам и уважение.
Основы Fibre Channel
Продолжаю вещать на тему прояснения основных представлений об FC SAN. В комментариях к первому посту меня попрекнули тем, что копнул недостаточно глубоко. В частности — мало сказал о непосредственно FC и ничего о BB credits, IP и multipathing. Multipathing и IP — темы для отдельных публикаций, а про FC, пожалуй, продолжу. Или начну, как посмотреть.
Для начала, небольшое терминологическое отступление (навеянное опять же комментарием к предыдущему посту).
Fibre or Fiber?: Изначально технология Fibre Channel предполагала поддержку только волоконно-оптических линий (fiber optic). Однако, когда добавилась поддержка меди, было принято решение название в принципе сохранить, но для отсылки на стандарт использовать британское слово Fibre. Американское Fiber сохраняется преимущественно для отсылки на оптоволокно.
IBM Redbook «Introduction to SAN and System Networking»
Начало
По аналогии с сетевой моделью OSI, Fibre Channel состоит из пяти уровней. Каждый уровень обеспечивает определённый набор функций.

FC-0 — уровень физических интерфейсов и носителей. Описывает физическую среду: кабели, коннекторы, HBA, трансиверы, электрические и оптические параметры.
А теперь подробнее об этих и других непонятных словосочетаниях. В данной статье рассмотрим только нижние три уровня, как наиболее значимые при создании и управлении инфраструктурой FC SAN.
Я, пожалуй не буду приводить сложных таблиц разновидностей кабелей, передатчиков и их характеристик. Во-первых, потому что неудобно тут вставлять таблицы, во-вторых, потому что эти таблицы есть везде, где хоть что-то написано про FC (русская википедия, нерусская википедия), в-третьих (и ключевое), — на мой взгляд, главное понять суть, а справочные данные найти не проблема.
А суть в том, что есть два типа волокна: многомодовое и одномодовое.
Многомодовое (Multimode Fiber, MMF) — относительно широкое в сечении (50-62,5 микрон), предназначенное для коротковолновых лазерных лучей. «Многомодовое» значит, что свет по каналу может проходить разными путями — множественно отражаясь от стенок волокна. Это делает кабель менее чувствительным к перегибу, но снижает силу и качество сигнала, что ограничивает данный тип только небольшими дистанциями — до 500 м.
Одномодовое (Singlemode Fiber, SMF) — волокно малого диаметра (8-10 микрон), сигнал по которому передаётся длинноволновым лазером, свет которого не виден человеческому глазу. Тут свет может перемещаться единственным путём — по прямой, соответственно сигнал передаётся быстрее и точнее, но оборудование для обеспечения такого рода сигналов стоит значительно дороже, так что используется, в основном, для связи на больших расстояниях (до 50 км). К перегибам и вообще любым искривлениям одномодовое волокно куда чувствительнее.
Тут рядом есть более подробная статья про типы волокна.
Стоит иметь ввиду, что для соединения двух устройств используется два кабеля. Один используется для передачи, другой для приёма. Потому важно подключить их корректно (Tx одной стороны к Rx другой).
Отдельно хочу упомянуть про такой термин как тёмная оптика (dark fiber). Сей термин не значит, что она как-то специальным образом тонирована. Это просто выделенные оптические линии связи, как правило, для связи на больших расстояниях (между городами или далеко отстоящими зданиями), которые берутся в аренду, и для использования которых не требуется дополнительное оборудования усиления сигнала (его обеспечивает владелец). Однако, так как это просто оптический кабель, отданный в ваше полновластное распоряжение, до тех пор пока вы не пустите по нему свой световой сигнал, он остаётся «тёмным».
ASIC (аббревиатура от англ. application-specific integrated circuit, «интегральная схема специального назначения») — интегральная схема, специализированная для решения конкретной задачи. В отличие от интегральных схем общего назначения, специализированные интегральные схемы применяются в конкретном устройстве и выполняют строго ограниченные функции, характерные только для данного устройства; вследствие этого выполнение функций происходит быстрее и, в конечном счёте, дешевле. Примером ASIC может являться микросхема, разработанная исключительно для управления мобильным телефоном, микросхемы аппаратного кодирования/декодирования аудио- и видео-сигналов (сигнальные процессоры).
Transceivers, трансиверы или SFP — в случае FC-коммутаторов это отдельные модули, необходимые для подключения кабеля к порту. Различаются на коротковолновые (Short Wave, SW, SX) и длинноволновые (Long Wave, LW, LX). LW-трансиверы совместимы с многомодовым и одномодовым волокном. SW-трансиверы — только с многомодовым. И к тем и к другим кабель подключается разъёмом LC.
Есть ещё SFP xWDM (Wavelenght Division Multiplexing), предназначенные для передачи данных из нескольких источников на дальние расстояния единым световым пучком. Для подключения кабеля к ним используется разъём SC.
8/10 и 64/66
Первое, что происходит на этом уровне — кодирование / декодирование информации. Это довольно мудрёный процесс, в ходе которого каждые 8 бит поступающей информации преобразуются в 10-битное представление. Делается это с целью повышения контроля целостности данных, отделения данных от служебных сигналов и возможности восстановления тактового сигнала из потока данных (сохранение баланса нулей и единиц).
Это ведёт к заметному снижению полезной пропускной способности, ибо как можно подсчитать, 20% потока данных является избыточной служебной информацией. А ведь кроме всего прочего, немалую часть этого потока может занимать служебный трафик.
Однако хорошая новость в том, что кодирование 8/10 используется в оборудовании 1G, 2G, 4G и 8G. В части реализаций 10G и начиная с 16G кодирование осуществляется по принципу 64/66, что существенно увеличивает полезную нагрузку (до 97% против 80% в случае 8/10).
Ordered sets
Инициализация соединения (Link initialization)
Фреймы (Кадры, Frames)
Промежутки между фреймами заполняются специальными «заполняющими словами» — fill word. Как правило, это IDLE, хотя начиная с FC 8G было стандартизовано использование ARB(FF) вместо IDLE, в целях снижения электрических помех в медном оборудовании (но по-умолчанию коммутаторами используется IDLE).
Последовательности (Sequences)
Чаще всего источник стремится передать приёмнику гораздо больше информации, чем 2112 байт (максимальный объём данных одного фрейма). В этом случае информация разбивается на несколько фреймов, а набор этих фреймов называется последовательностью (sequence). Чтобы в логическую последовательность фреймов не вклинилось что-то лишнее при параллельной передаче, заголовок каждого фрейма имеет поля SEQ_ID (идентификатор последовательности) и SEQ_CNT (номер фрейма в последовательности).
Обмен (Exchange)
Одна или несколько последовательностей, отвечающих за какую-то одиночную операцию, называется обменом. Источник и приёмник могут иметь несколько параллельных обменов, но каждый обмен в единицу времени может содержать только одну последовательность. Пример обмена: инициатор запрашивает данные (последовательность 1), таргет возвращает данные инициатору (последовательность 2) и затем сообщает статус (последовательность 3). В этот набор последовательностей не может вклиниться какой-то посторонний набор фреймов.
Для контроля этого процесса заголовок каждого фрейма включает поля OX_ID (Originator Exchange ID — заполняется инициатором обмена) и RX_ID (Responder Exchange ID — заполняется получателем в ответных фреймах, путём копирования значения OX_ID).
Классы обслуживания (Classes of Services)
Различные приложения предъявляют разные требования к уровню сервиса, гарантии доставки, продолжительности соединения и пропускной способности. Некоторым приложениям требуется гарантированная пропускная способность в течение их работы (бэкап). Другие имеют переменную активность и не требуют постоянной гарантированной пропускной способности канала, но им нужно подтверждение в получении каждого отправленного пакета. Для удовлетворения таких потребностей и обеспечения гибкости, FC определяет следующие 6 классов обслуживания.
Class 1
Для этого класса устанавливается выделенное соединение, которое резервирует максимальную полосу пропускания между двумя устройствами. Требует подтверждения о получении. Требует чтобы фреймы попадали на приёмник в том же порядке, что вышли из источника. Ввиду того, что не даёт другим устройствам использовать среду передачи, используется крайне редко.
Class 2
Без постоянного соединения, но с подтверждением доставки. Не требует соответствия порядка отправленных и доставленных фреймов, так что они могут проходить через фабрику разными путями. Менее требователен к ресурсам, чем класс 1, но подтверждение доставки приводит к повышенной утилизации пропускной способности.
Class 3
Без постоянного соединения и без подтверждения доставки. Самый оптимальный с точки зрения использования ресурсов фабрики, но предполагает, что протоколы верхних уровней смогут собрать фреймы в нужном порядке и перезапросить передачу пропавших фреймов. Наиболее часто используемый.
Class 4
Требует постоянного соединения, подтверждение и порядок фреймов как и класс 1. Главное отличие — он резервирует не всю полосу пропускания, а только её часть. Это гарантирует определённое QoS. Подходит для мультимедиа и Enterprise-приложений, требующих гарантированного качества соединения.
Class 5
Ещё до конца не описан и не включен в стандарт. Предварительно, класс, не требующий соединения, но требующий немедленной доставки данных по мере их появления, без буферизации на устройствах.
Class 6
Вариант класса 1, но мультикастовый. То есть от одного порта к нескольким источникам.
Class F
Класс F определён в стандарте FC-SW для использования в межкоммутаторных соединениях (Interswitch Link, ISL). Это сервис без постоянного соединения с уведомлениями о сбое доставки, использующийся для контроля, управления и конфигурирования фабрики. Принцип похож на класс 2, но тот используется для взаимодейтсвия между N-портами (порты нод), а класс F — для общения E-портов (межкоммутаторных).
Flow Control
В целях предотвращения ситуации, когда отправитель перегрузит получателя избыточным количеством фреймов так, что они начнут отбрасываться получателем, FC использует механизмы управления потоком передаваемых данных (Flow Control). Их два — Buffer-to-Buffer flow control и End-to-End flow control. Их использование регламентируется классом обслуживания. Например, класс 1 использует только механизм End-to-End, класс 3 — Buffer-to-Buffer, а класс 2 — оба эти механизма.
Buffer-to-Buffer flow control
Принцип технологии — кредит в каждый дом отправка любого фрейма должна быть обеспечена наличием кредита на отправку.
Все поступающие на вход порта фреймы помещаются в специальную очередь — буферы. Количество этих буферов определяется физическими характеристиками порта. Один буфер (место в очереди) соответствует одному кредиту. Каждый порт имеет два счётчика кредитов:
TX BB_Credit — счётчик кредитов передачи. После отправки каждого фрейма, уменьшается на 1. Если значение счётчика стало равным нулю — передача невозможна. Как только от порта-приёмника получено R_RDY, счётчик увеличивается на 1.
RX BB_Credit — счётчик кредитов приёма. Как только фрейм принят и помещён в буфер, уменьшается на 1. Когда фрейм обрабатывается или пересылается дальше, счётчик увеличивается на 1, а отправителю отправляется R_RDY. Если значение счётчика падает до 0, то в принципе, приём новых фреймов должен быть прекращён. На практике, из-за ошибок синхронизации кредитов может возникнуть ситуация, что источник прислал ещё один-несколько фреймов уже после того как RX BB_credit стал равен нулю. Данная ситуация называется buffer overflow. В большинстве реализаций порт обрабатывает такие ситуации «по-доброму» — за счёт резервных буферов. Хотя некоторое оборудование в таких случаях может сынициировать Link Reset.
Отсюда исходит сильное влияние расстояния между портами на производительность. Чем выше расстояние и больше пропускная способность, тем больше фреймов будет отправлено (читай кредитов передачи потрачено) ещё до того как получатель получит хотя бы первый. Ситуацию облегчает особенность архитектуры FC-коммутаторов. Дело в том, что количество буферов не закреплено жёстко за каждым портом (кроме восьми обязательных), а является общим для всех. И в случае определения «дальних линков» (автоматически или вручную) количество выделяемых коммутатором буферов для этого порта увеличивается. Другой плюс общей памяти — не требуется гонять буферы от одного порта к другому внутри коммутатора.
End-to-End flow control
Реализуется счётчиком EE_Credit, который определяет максимум фреймов, которые источник может отправить приёмнику без получения подтверждения (Acknowledge, ACK). В отличие от BB_Credit распространяется только на фреймы с данными, а обмен/учёт происходит между конечными нодами.
Конец
Изначально мне казалось, что статья будет раза в два меньше, но в ходе написания всплыло много деталей, без которых счастье казалось не полным. Ещё кучу вещей, которые хотелось бы осветить, пришлось пока отбросить — процесс написания грозил стать бесконечным. Если у кого-то возникнут замечания, предложения и пожелания к тому, про что ещё стоит написать, буду признателен. И спасибо всем, кто дочитал до этого места.
Были использованы материалы из следующих источников:
IBM Redbook «Introduction to SAN and System Networking»
EMC «Network Storage Concepts and Protocols»
Brocade «SAN Fabric Administration Best Practices Guide»



