Поиск текста в файлах Linux
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux всё это делается с помощью одной очень простой, но в то же время мощной утилиты grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим, как выполняется поиск текста в файлах Linux, подробно разберём возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Утилита grep решает множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [имя файла. ]
$ команда | grep [опции] шаблон
Возможность фильтровать стандартный вывод пригодится,например, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном отчёте утилиты ps.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
grep User /etc/passwd
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
grep «^Nov 10» messages.1
Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s
Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0), stratum 10
grep «terminating.$» messages
Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating.
Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
Найдём все строки, которые содержат цифры:
grep «4» /var/log/Xorg.0.log
Рекурсивное использование grep
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ServerName zendsite.localhost
DocumentRoot /var/www/localhost/htdocs/zendsite
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Поиск двух слов
Можно искать по содержимому файла не одно слово, а два сразу:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Цветной вывод в grep
Также вы можете заставить программу выделять другим цветом вхождения в выводе:

Выводы
Вот и всё. Мы рассмотрели использование команды grep для поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Команда Grep в Linux (Поиск текста в файлах)
Grep Command in Linux (Find Text in Files)

Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показывать только имя файла
Вывод будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Показать номера строк
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
Печать строк перед сопоставлением
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Рекурсивный поиск
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показать только имя файла
Результат будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Показать номера строк
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Бесшумный режим
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Поиск нескольких строк (шаблонов)
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
Строки печати перед матчем
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.

Про Linux за 5 минут | Что это или как финский студент перевернул мир?
Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
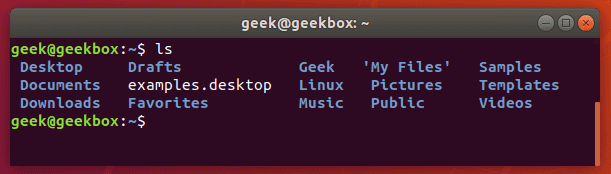
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
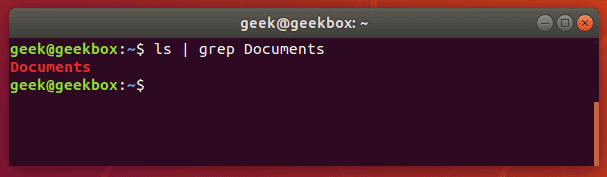
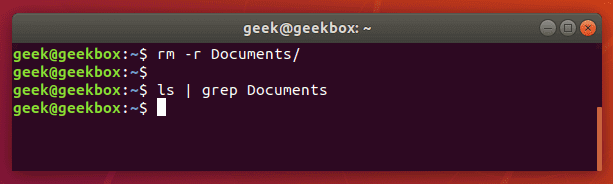
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
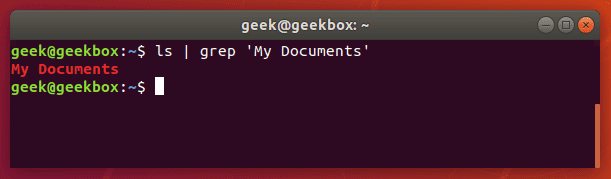
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
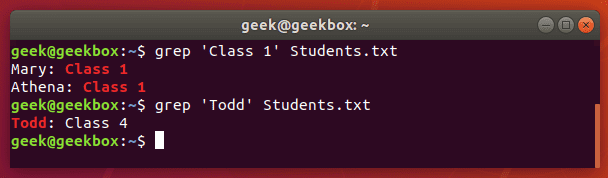
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
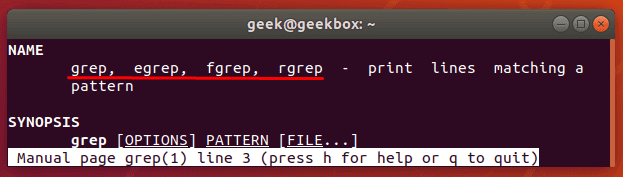
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
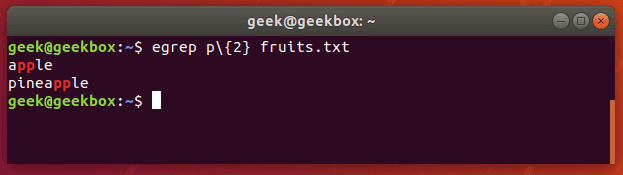
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
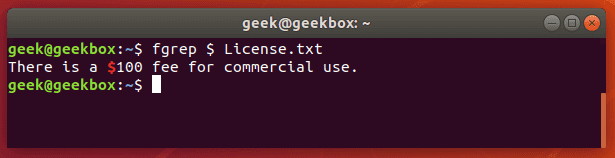
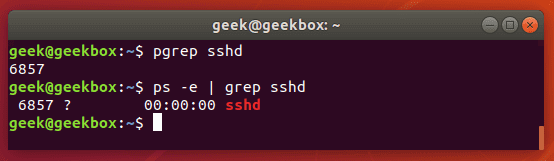
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
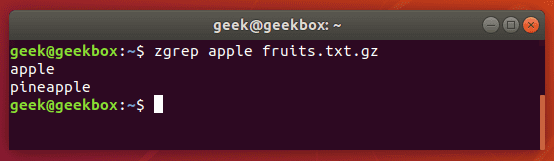
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
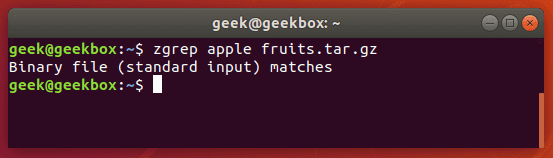
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
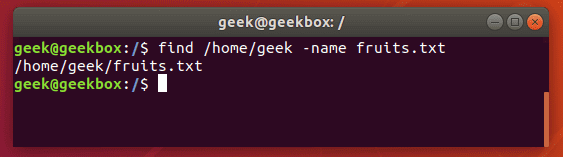
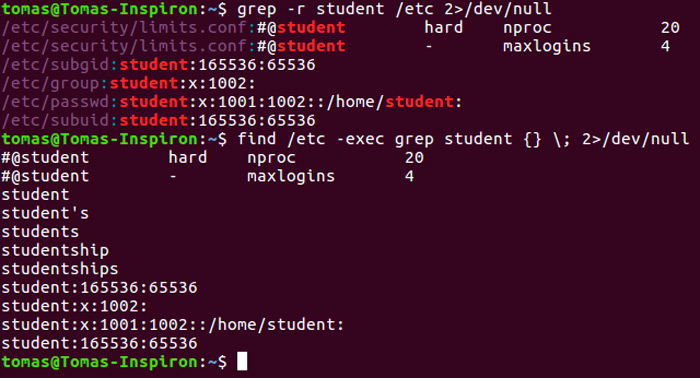
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

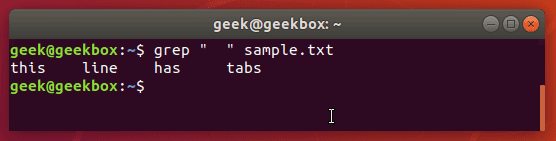
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
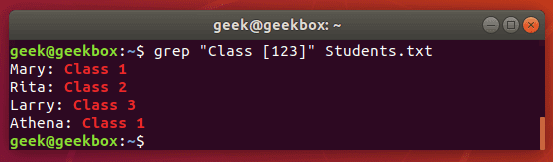
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
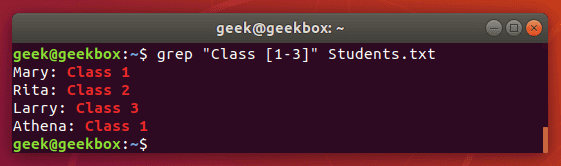
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
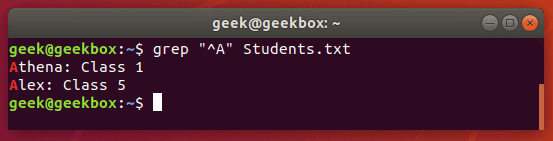
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
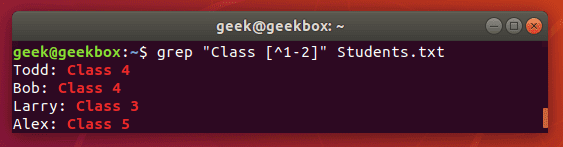
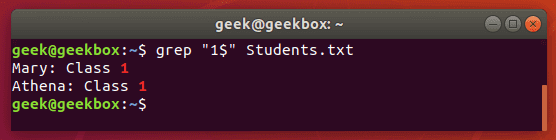
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Правила использования операторов grep и find в Linux
Изначально операционные системы Unix/Linux не имели графического интерфейса, поскольку были ориентированы на серверное применение. Сегодня в этом плане они мало в чём уступают Windows, из-за чего пользователи, использующие эту ОС, редко знают синтаксис и назначение основных команд Linux. Между тем это весьма мощный инструмент, позволяющий быстро выполнять операции, которые с помощью базовых средств ОС выполнить проблематично или невозможно. Сегодня вы познакомитесь с операторами find и grep, являющимися базовыми для файловой системы всех дистрибутивов Linux.
Назначение операторов find и grep
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Синтаксис grep и find
Начнём с оператора find. Синтаксис файловой поисковой команды выглядит так:
find [где искать] [параметры] [-опции] [действия]
Некоторые употребительные параметры:
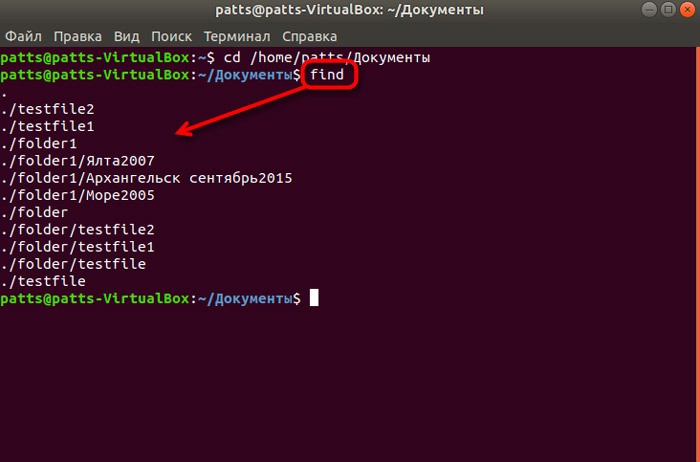
Перечень доступных опций (указываются через дефис):
grep [опции] шаблон [где искать]
Под опциями следует понимать дополнительные уточняющие параметры, например, использование инверсного режима или поиск заданного количество строк.
В шаблоне указывается, что нужно искать, используя непосредственно заданную строку или регулярное выражение.
Возможность использования регулярных выражений позволяет существенно расширить возможности поиска. Указание стандартного вывода может оказаться полезным, если стоит задача отфильтровать ошибки, записанные в логи, или для поиска PID процесса в результатах выполнения команды ps, которые могут быть многостраничными.
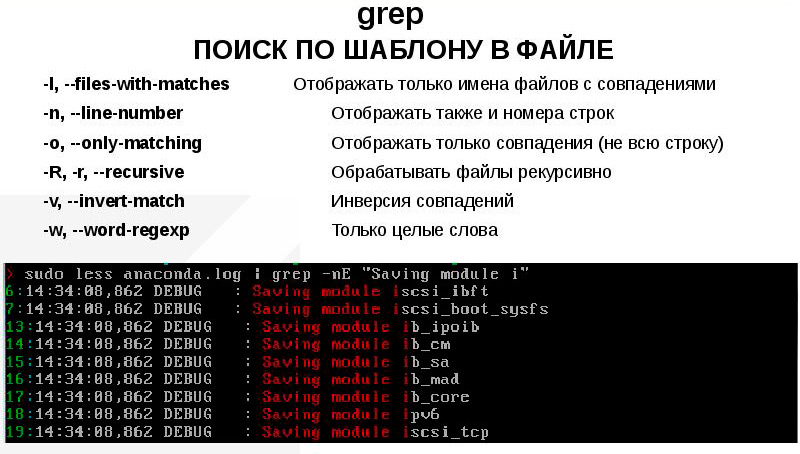
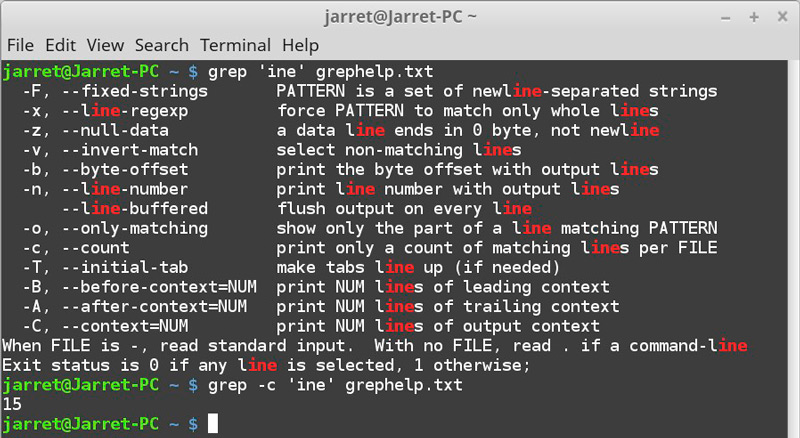
Рассмотрим наиболее употребительные параметры grep:
Теперь имеет смысл перейти от теоретической части к практической.3
Примеры использования утилит
Если вы знаете, что такое комбинаторика, то должны представлять истинное количество возможных комбинаций команд поиска. Мы ограничимся только наиболее полезными примерами, которые могут вам пригодиться при работе.
Поиск текста в файлах
Пускай мы имеем права администратора и перед нами поставлена задача отыскать конкретного пользователя в огромном файле паролей. Нам понадобится довольно простая команда с указанием пути размещения файла:
grep NameUser /etc/passwd
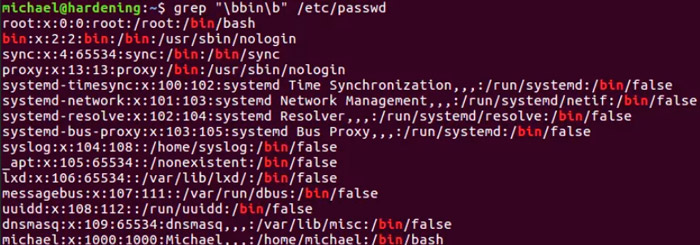
Если результат поиска будет положительным, мы получим результирующую строку примерно следующего вида:
NameUser:x:1021:1021: NameUser. /home/User:/bin/bash
Если потребуется осуществить поиск фрагмента текста без учёта регистра символов, команда будет выглядеть так:
В этом случае будет найден и пользователь NameUser, и его «однофамилец» nameuser, а также все другие возможные комбинации.
Вывод нескольких строк
Пускай нам нужно вывести все ошибки из лога оконной оболочки Xorg.log. Задача осложняется тем, что после ошибочной может следовать строка, содержащая ценные сведения. Она решается, если мы заставим команду отображать несколько строк, используя в качестве шаблона строку «РР»:
grep –A5 «РР» /var/log/xorg.0.log
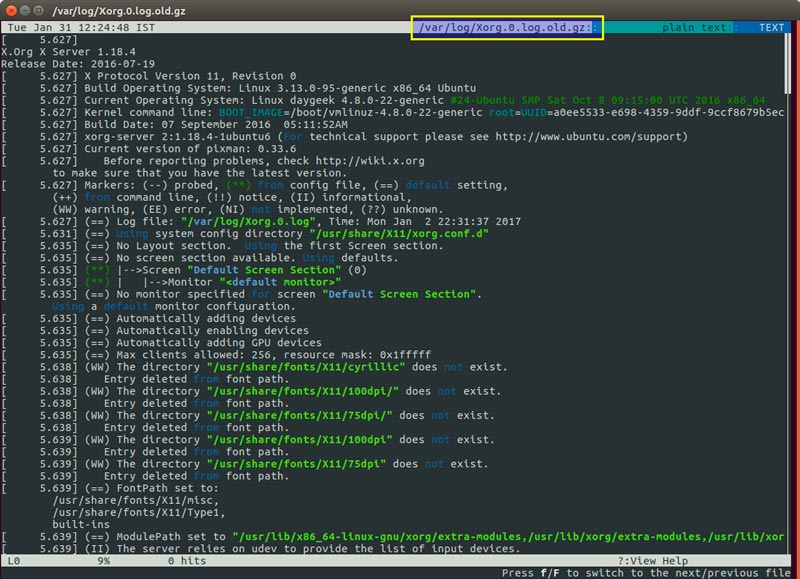
Получим строку, содержащую шаблон и 5 строк после неё.
grep –C3 «РР» /var/log/xorg.0.log
Вывод строки с фрагментом текста и тремя строками до и после.
Использование в grep регулярных выражений
Пускай нам в файле messages.2 нужно выловить все строки за сентябрь:
Итог будет примерно таким:
Sep 09 01:11:45 gs124 ntpd[2243]: time reset +0.197579 s
Sep 09 01:19:10 gs124 ntpd[2243]: time reset +0.203484 s
Для поиска шаблона, расположенного в конце строки фала, используется символ «$»:
grep «term.$» messages
Jun 17 19:01:19 cloneme kernel: Log daemon term.
Sep 11 06:30:54 cloneme kernel: Log daemon term.
А вот пример использования регулярного выражения, позволяющего выполнить поиск строк, содержащих любые цифры, кроме нуля:
grep «5» /var/log/Xorg.1.log
Использование рекурсивного поиска в grep
Результат может быть примерно таким:
Поиск слов
Поиск двух или нескольких слов
Усложним задачу: нам нужно найти все строки, где встречается два слова. Команда будет такой:
Количество вхождений строки
Инвертированный поиск с помощью grep
Иногда задача поиска с использованием grep по содержимому файлов имеет цель найти не само вхождение, а строки, где этот фрагмент отсутствует. Нам поможет опция –v:
Вывод имени файла
Цветной вывод с использованием grep
Выделение другим цветом – отличный способ визуализировать искомое вхождение, существенно снижающий нагрузку на глаза, если операция выполняется часто. Оказывается, grep имеет опцию и для такого вывода результатов поиска:
Переходим к рассмотрению примеров использования утилиты find в Linux.
Поиск всех файлов
Для вывода списка файлов, расположенных в текущем каталоге, используем команду в следующем формате:
Если необходимо показать полное имя файлов, используем команду
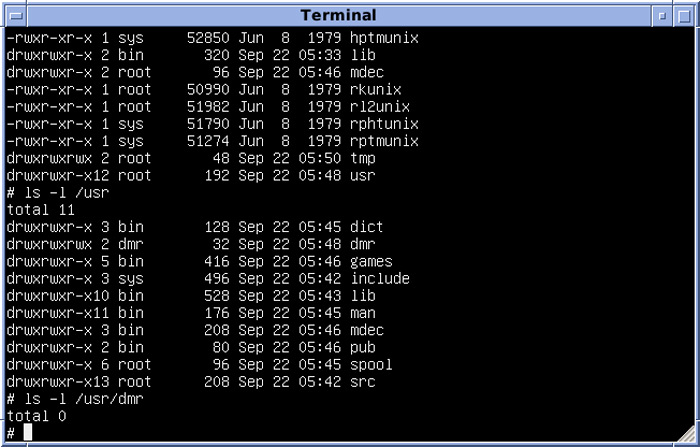
Вывод файлов в заданном каталоге
Для поиска файлов в определенной пользователем папке используем команду
А вот как можно найти файлы, содержащие в имени заданный фрагмент, в текущем каталоге:
Если поиск нужно осуществить без учёта регистра, команду нужно модифицировать:
Не учитывать регистр при поиске по имени:
Ограничение глубины поиска
Ещё одна достаточно типичная задача – поиск файлов в конкретной папке по заданному имени:
Инвертирование шаблона
Мы уже рассматривали аналог команды для поиска строк, не содержащих заданный фрагмент. Точно так же можно поступить и с файлами, не соответствующими заданному шаблону:
Поиск по нескольким критериям
Приводим пример командной строки с использованием утилиты find для поиска по двум критериям с использованием оператора not (исключение):
В этом случае будут найдены файлы, имя которых включает фрагмент user, но у которых расширение – не html. Вместо оператора исключения можно использовать логическое «И»/»ИЛИ»:
В этом случае мы получим полный список файлов с обоими расширениями, расположенными в текущей директории.
Поиск в нескольких каталогах
Если нам нужно найти файлы в двух каталогах, просто указываем из через пробел:
Поиск скрытых файлов
В Linuxе, как и в Виндовс, существуют скрытые файлы, которые при использовании команды find без специального символа показываться не будут. Этот символ – «тильда», а директива будет иметь следующий вид:
Поиск файлов в Linux по разрешениям
Иногда возникает потребность фильтрации каталога по определённой маске прав. Например, если нам нужно найти файлы с атрибутом 0661, используем команду:
Задача фильтрации файлов с атрибутом «только для чтения» решается так:
А вот как будет выглядеть поиск исполняемых файлов в каталоге etc:
Поиск файлов по группах/пользователях
Администратору часто приходится сталкиваться с задачей поиска файлов, являющихся собственностью конкретного пользователя и/или группы. Поиск по юзеру:
Для групп пользователей используется другой параметр:
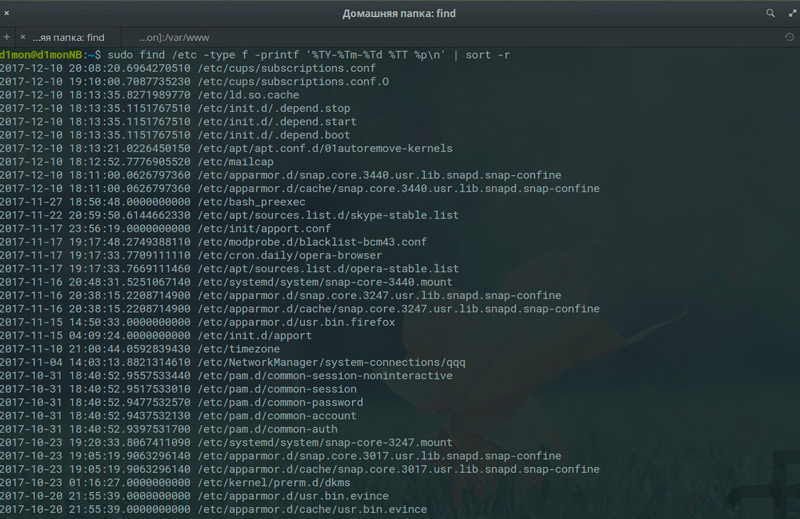
Поиск по дате последней модификации
Видимый формат даты файла в ОС Linux как раз и относится к дате его модификации (такой же принцип используется и в Windows). Для формирования списка по дате применяется опция mtime. Допустим, нам нужно отыскать файлы, изменённые два месяца назад:

В числе атрибутов файла есть и дата его последнего открытия (без внесения изменений). Такие файлы выводятся следующей командой:
Можно также задавать промежуток времени. Для поиска файлов, модифицированных в промежутке от четырёх до двух месяцев назад, используем директиву:
А вот как найти свежеизменённые файлы (двухчасовой давности):
Поиск файлов по размеру
Подозреваете, что кто-то использует диск для размещения фильмов? Ищем файлы размером 1.4 ГБ:
Или используем диапазон:
Поиск пустых файлов/каталогов
Да, не удивляйтесь. Задача наведения порядка на носителе характерна не только для ОС Android. В Linux она решается с помощью такой директивы:
Пример действий с найденными файлами
В Linux команда find рекурсивно может выполнять определённые действия с теми файлами, поиск которых вы ведёте. Для выполнения файловых команд нужно использовать параметр exec. Так, директива для показа информации обо всех файлах с использованием команды ls будет выглядеть так:
А вот как просто можно удалить временные файлы с заданной маской в директории /home/temp:
Безусловно, для новичка использование для поиска командной строки с огромным числом опций покажется несколько вычурным способом, но в Linux это в порядке вещей. А как бы вы решали описанные здесь задачи в Windows? То-то же. В этом аспекте Linux явно впереди.



