Как найти все файлы, содержащие определённый текст (на Linux)
Иногда бывают ситуации, когда нужно просканировать всю файловую систему Linux и найти все файлы, содержащие определённую строку текста. То есть нужно выполнить поиск не по имени файла, а по содержимому текстового файла.
Пример таких ситуаций из практики:
Пример — поиск заголовка Strict-Transport-Security в директории конфигурационных файлов веб-сервера:

Одним из лучших вариантов поиска всех файлов, содержащих заданный текст, является команда:
В этой команде используются следующие опции:
-r (также можно использовать -R) для рекурсивного поиска — то есть поиск будет выполнен в папке и подпапках. Опция -R делает так, что программа следует по символическим ссылкам, если натыкается на них, соответственно, с опцией -r этого не происходит. Но поиск является рекурсивным в обоих случаях
-n означает выводить номера строку (чтобы быстрее найти в них нужное место)
-w используется для поиска по полным словам. При использовании опции -w будут выбраны только строки, которые содержат совпадения целых слов. То есть для того, чтобы совпадение засчиталось, совпавшая подстрока быть либо вначале строки, либо перед ней должен идти несловесный составной символ. Аналогично она должна быть либо в конце строки, либо за ней должен следовать несловесный составной символ. Словесными составными символами являются буквы, цифры и подчёркивание. Соответственно, несловесными являются все остальные: пробелы, знаки препинания, дефисы и прочее.
Эти опции являются оптимальными, но, на самом деле, для поиска по всей директории вместе с вложенными поддиректориями, либо по всей файловой системе, достаточно использовать только опцию -r, а остальные можно пропустить.
Рассмотрим ещё несколько опций, которые могут оказаться весьма полезными:
-i для игнорирования регистра букв (по умолчанию ищутся буквы в точно таком же регистре, как и в шаблоне). Но обратите внимание, что эта опция очень сильно замедляет скорость поиска.
-l (маленькая L) подавляет нормальный вывод; вместо него выводится имя каждого файла, в котором найдено совпадение. То есть по умолчанию выводиться совпавшая строка, а с этой опцией будут выводиться только имена файлов, в которых найдена строка. Сканирование будет остановлено после первого совпадения.
—color[=КОГДА], —colour[=КОГДА] — используется для подсветки в терминале совпавшей подстроки, контекстных строк, имён файлов, номеров строк, байтового смещения и разделителей (для полей и групп контестных строк). КОГДА можно указывать или не указывать по жоеланию. В качестве КОГДА может быть never (никогда), always (всегда) или auto (автоматически).
-I — пропускать бинарные файлы. При рекурсивной обработке могут попадаться не текстовые файлы, натыкаясь на которые grep будет показывать предупреждения. Эта опция делает обработку бинарных файлов такой, как если бы они не содержали совпадающих данных.
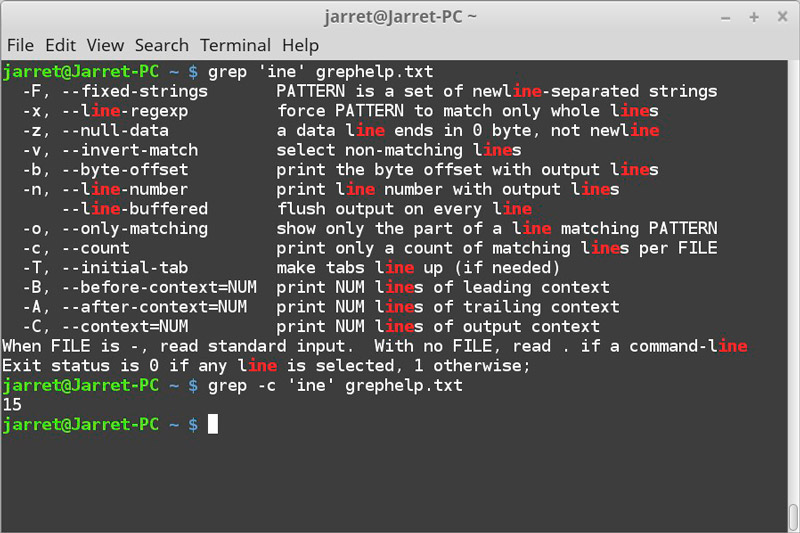
В качестве шаблона grep используются регулярные выражения — они являются крайне мощным инструментом для поиска строк. Тем не менее, если вы не умеете пользоваться регулярными выражениями, то вы можете получить не те результаты, которых ожидаете, поскольку некоторые символы в регулярных выражениях имеют специальное значение. По этой причине рекомендуется ознакомиться с большой понятной инструкцией «Регулярные выражения и команда grep».
Ещё один вариант — использовать опцию -F. Она будет интерпретировать ШАБЛОНЫ как фиксированные строки, а не как регулярные выражения. С одной стороны, команда grep потеряет часть своей гибкости, но при этом вы получите более предсказуемый результат, если вы не понимаете регулярные выражения.
В зависимости от обстоятельств, можно использовать для повышения эффективности поиска следующие флаги:
—exclude=GLOB — означает пропустить файлы, с именем суффикса, которое совпадёт с шаблоном GLOB. Имя суффикса это как полное имя, так и любой суффикс, начинающийся после / и перед не-/ (то есть между слэшей в пути имени файла). При рекурсивном поиске, пропускаются все подфайлы, чьё базовое имя совпадает с GLOB. Базовое имя — это часть после последнего слэша (/). Шаблон GLOB поддерживает несколько подстановочных символов. Шаблон (GLOB) может использовать в качестве подстановочных символов * (означает последовательность нуля или более символов), ? (означает ровно один символ), и [СИМВОЛЫ] (означает любой один из СИМВОЛОВ), (означает любой из символов), а также \ для экранирования подстановочных символов или символа обратного слэша, чтобы они начали восприниматься буквально.
—include=GLOB — искать только файлы, чьё базовое имя совпадает с GLOB (можно использовать подстановочные символы, как описано чуть выше)
—exclude-dir=GLOB — пропустить директории с суффиксом имени, которые совпадает с шаблоном GLOB. При рекурсивном поиски, пропуск любых поддиректорий, чьё базовое имя совпадает с GLOB. Любые избыточные конечные слэши в GLOB игнорируются.
В этой команде * (звёздочка) означает любое имя файла. Но эта звёздочка экранирована, поскольку для терминала она также имеет особое значение. В этом имене должна идти точка и буква c или h.
Следующий поиск исключит из результатов все файлы, которые заканчиваются на расширение .o:
Для директорий возможно исключить конкретную директорию(ии) через параметр —exclude-dir. Например, следующая команда исключит dirs dir1/, dir2/ и все другие директории соответствующие *.dst/:
Поиск текста в файлах на LINUX

Сегодня в статье рассмотрим как можно выполнить поиск текста в файлах на Linux.
Возникаю такие ситуации, когда необходимо найти текст в файле или же какой либо файл. В Linux всё это делается с помощью незаменимой утилиты grep. С помощью данной утилиты можно искать текст в файлах, фильтровать вывод команд и много чего ещё.
grep (global regular expression print) — одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. Grep в считанные секунды найдёт файл, или текст в файле, или отфильтрует вывода другой утилиты.
ОПЦИИ
Давайте рассмотрим самые основные опции утилиты grep, которые помогут нам выполнять поиск текста в файлах:
Примеры использования
Давайте рассмотрим несколько примеров поиска текста внутри файлов с помощью grep.
Поиск текста в файле
В первом примере мы будем искать пользователя smirnov в файле расположенных по пути /home/passwd :
Данная команда выдаст приблизительно вот такой результат:
Из данного вывода мы видим, что команда grep обнаружила в файле /etc/passwd пользователя smirnov и вывела сопутствующею информацию.
Поиск текста в файлах и директориях.
Давайте попробуем найти искомую комбинацию obu4alka.ru во всех файлах расположенных в директории /etc/nginx и её поддиректориях. Для этого нам необходимо воспользоваться рекурсивным поиском, опция -r:
В выводе вы получим:
Поиск текста в файлах определенного слова.
Если вы ищете определённое слово в файлах, например mytext, то grep выведет также 123mytext, mytext123, 12mytext34 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова, воспользовавшись опцией -w:
Поиск текста в файлах двух слов
Можно искать по содержимому файла не одно слово, а сразу два:
Команда выдаст результат по двум запросам:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение function :
Цветной вывод поиска в grep
Также вы можете заставить программу выделять другим цветом вхождения в выводе:
Примеры использования grep
Сегодня мы с вами рассмотрели использование команды grep для поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках.
Если есть вопросы, то пишем в комментариях.
Также можете вступить в Телеграм канал, ВК или подписаться на Twitter. Ссылки в шапки страницы.
Заранее всем спасибо.
Правила использования операторов grep и find в Linux
Изначально операционные системы Unix/Linux не имели графического интерфейса, поскольку были ориентированы на серверное применение. Сегодня в этом плане они мало в чём уступают Windows, из-за чего пользователи, использующие эту ОС, редко знают синтаксис и назначение основных команд Linux. Между тем это весьма мощный инструмент, позволяющий быстро выполнять операции, которые с помощью базовых средств ОС выполнить проблематично или невозможно. Сегодня вы познакомитесь с операторами find и grep, являющимися базовыми для файловой системы всех дистрибутивов Linux.
Назначение операторов find и grep
Команда find в Linux является оператором командной строки для работы с файлами в обход существующей иерархии. Она позволяет производить поиск файлов с использованием множества фильтров, а также выполнять некие действия над файлами после их успешного поиска. Среди критериев поиска файлов – практически все доступные атрибуты, от даты создания до разрешения.
Команда grep в Linux также относится к поисковым, но внутри файлов. Буквальный перевод команды – «глобальная печать регулярных выражений», но под печатью здесь понимается вывод результатов работы на устройство по умолчанию, каковым обычно является монитор. Обладая огромным потенциалом, оператор используется достаточно часто и позволяет производить поиск внутри одного или нескольких файлов по заданным фрагментам (шаблонам). Поскольку терминология в Linuxе существенно отличается от таковой в среде Windows, очень многие пользователи испытывают значительные трудности с использованием этих команд. Постараемся устранить этот недостаток.
Синтаксис grep и find
Начнём с оператора find. Синтаксис файловой поисковой команды выглядит так:
find [где искать] [параметры] [-опции] [действия]
Некоторые употребительные параметры:
Перечень доступных опций (указываются через дефис):
grep [опции] шаблон [где искать]
Под опциями следует понимать дополнительные уточняющие параметры, например, использование инверсного режима или поиск заданного количество строк.
В шаблоне указывается, что нужно искать, используя непосредственно заданную строку или регулярное выражение.
Возможность использования регулярных выражений позволяет существенно расширить возможности поиска. Указание стандартного вывода может оказаться полезным, если стоит задача отфильтровать ошибки, записанные в логи, или для поиска PID процесса в результатах выполнения команды ps, которые могут быть многостраничными.
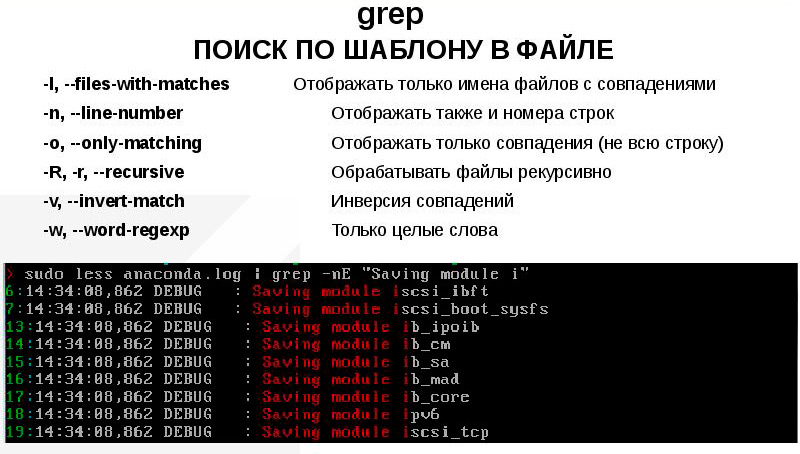
Рассмотрим наиболее употребительные параметры grep:
Теперь имеет смысл перейти от теоретической части к практической.3
Примеры использования утилит
Если вы знаете, что такое комбинаторика, то должны представлять истинное количество возможных комбинаций команд поиска. Мы ограничимся только наиболее полезными примерами, которые могут вам пригодиться при работе.
Поиск текста в файлах
Пускай мы имеем права администратора и перед нами поставлена задача отыскать конкретного пользователя в огромном файле паролей. Нам понадобится довольно простая команда с указанием пути размещения файла:
grep NameUser /etc/passwd
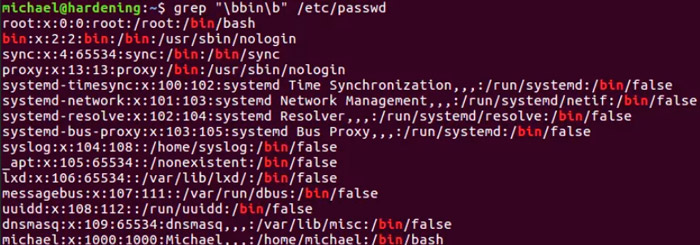
Если результат поиска будет положительным, мы получим результирующую строку примерно следующего вида:
NameUser:x:1021:1021: NameUser. /home/User:/bin/bash
Если потребуется осуществить поиск фрагмента текста без учёта регистра символов, команда будет выглядеть так:
В этом случае будет найден и пользователь NameUser, и его «однофамилец» nameuser, а также все другие возможные комбинации.
Вывод нескольких строк
Пускай нам нужно вывести все ошибки из лога оконной оболочки Xorg.log. Задача осложняется тем, что после ошибочной может следовать строка, содержащая ценные сведения. Она решается, если мы заставим команду отображать несколько строк, используя в качестве шаблона строку «РР»:
grep –A5 «РР» /var/log/xorg.0.log
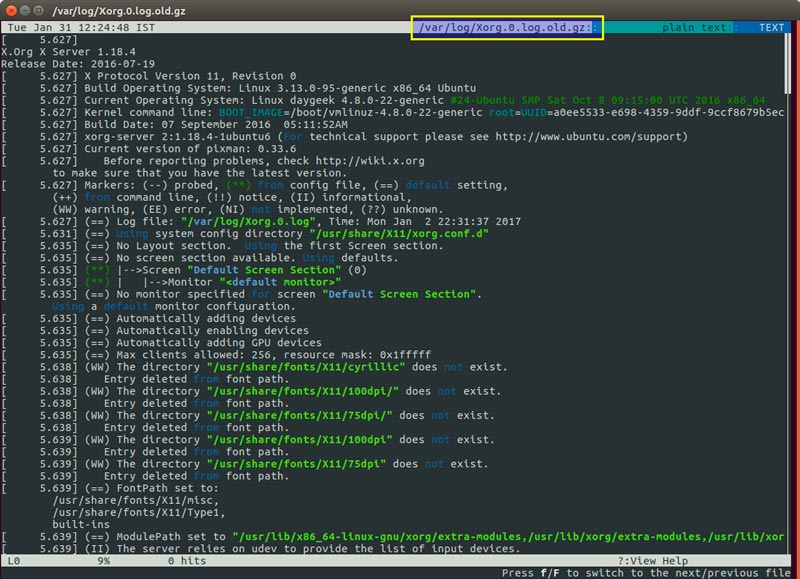
Получим строку, содержащую шаблон и 5 строк после неё.
grep –C3 «РР» /var/log/xorg.0.log
Вывод строки с фрагментом текста и тремя строками до и после.
Использование в grep регулярных выражений
Пускай нам в файле messages.2 нужно выловить все строки за сентябрь:
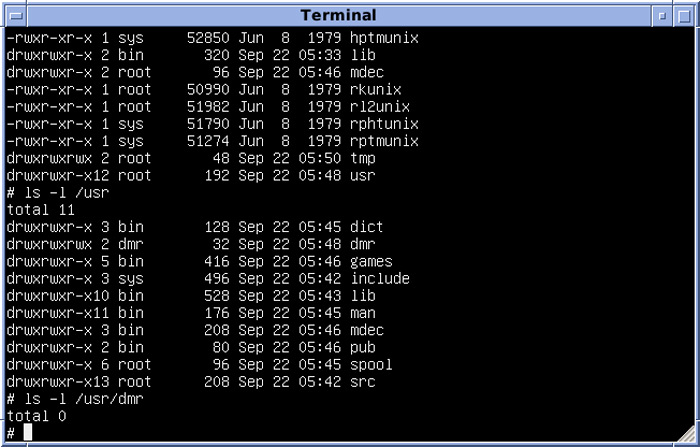
Итог будет примерно таким:
Sep 09 01:11:45 gs124 ntpd[2243]: time reset +0.197579 s
Sep 09 01:19:10 gs124 ntpd[2243]: time reset +0.203484 s
Для поиска шаблона, расположенного в конце строки фала, используется символ «$»:
grep «term.$» messages
Jun 17 19:01:19 cloneme kernel: Log daemon term.
Sep 11 06:30:54 cloneme kernel: Log daemon term.
А вот пример использования регулярного выражения, позволяющего выполнить поиск строк, содержащих любые цифры, кроме нуля:
grep «3» /var/log/Xorg.1.log
Использование рекурсивного поиска в grep
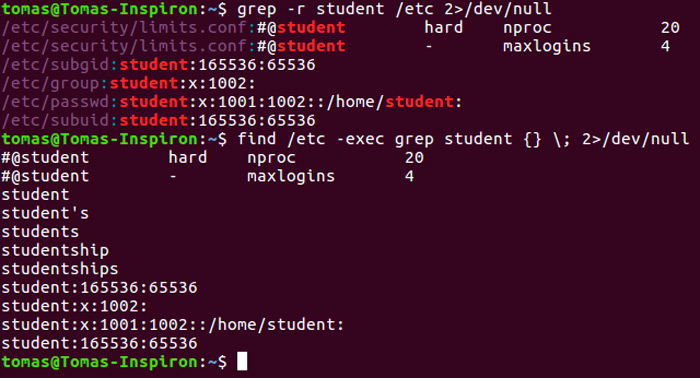
Результат может быть примерно таким:
Поиск слов
Поиск двух или нескольких слов
Усложним задачу: нам нужно найти все строки, где встречается два слова. Команда будет такой:
Количество вхождений строки
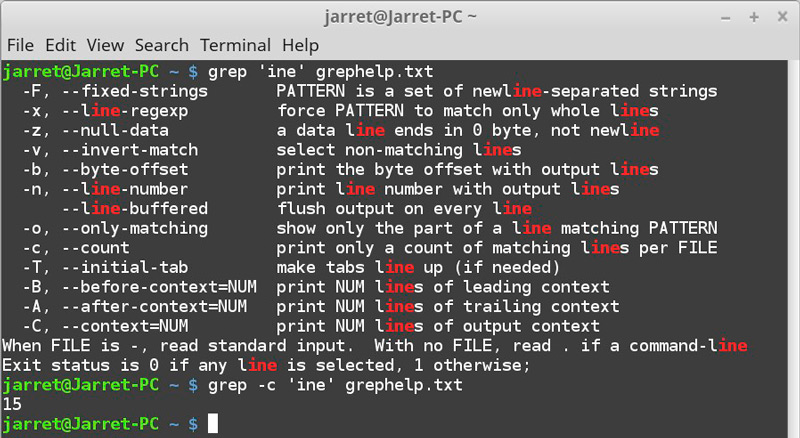
Инвертированный поиск с помощью grep
Иногда задача поиска с использованием grep по содержимому файлов имеет цель найти не само вхождение, а строки, где этот фрагмент отсутствует. Нам поможет опция –v:
Вывод имени файла
Цветной вывод с использованием grep
Выделение другим цветом – отличный способ визуализировать искомое вхождение, существенно снижающий нагрузку на глаза, если операция выполняется часто. Оказывается, grep имеет опцию и для такого вывода результатов поиска:
Переходим к рассмотрению примеров использования утилиты find в Linux.
Поиск всех файлов
Для вывода списка файлов, расположенных в текущем каталоге, используем команду в следующем формате:
Если необходимо показать полное имя файлов, используем команду
Вывод файлов в заданном каталоге
Для поиска файлов в определенной пользователем папке используем команду
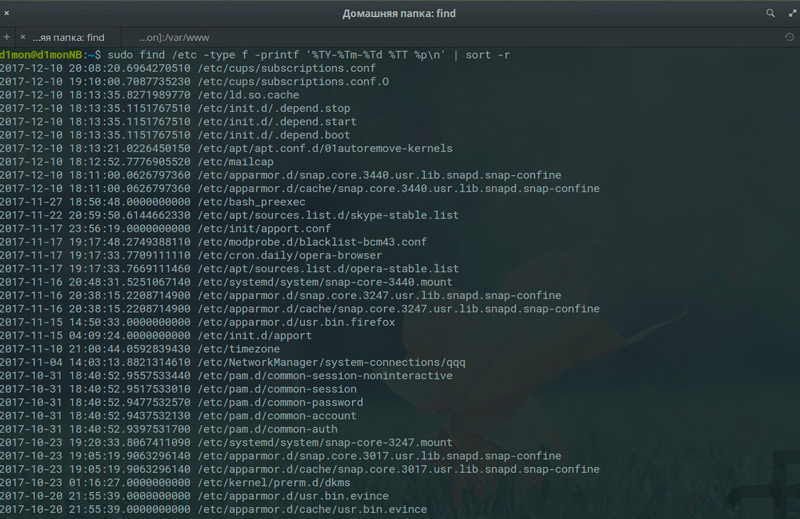
А вот как можно найти файлы, содержащие в имени заданный фрагмент, в текущем каталоге:
Если поиск нужно осуществить без учёта регистра, команду нужно модифицировать:
Не учитывать регистр при поиске по имени:
Ограничение глубины поиска
Ещё одна достаточно типичная задача – поиск файлов в конкретной папке по заданному имени:
Инвертирование шаблона
Мы уже рассматривали аналог команды для поиска строк, не содержащих заданный фрагмент. Точно так же можно поступить и с файлами, не соответствующими заданному шаблону:
Поиск по нескольким критериям
Приводим пример командной строки с использованием утилиты find для поиска по двум критериям с использованием оператора not (исключение):
В этом случае будут найдены файлы, имя которых включает фрагмент user, но у которых расширение – не html. Вместо оператора исключения можно использовать логическое «И»/»ИЛИ»:
В этом случае мы получим полный список файлов с обоими расширениями, расположенными в текущей директории.
Поиск в нескольких каталогах
Если нам нужно найти файлы в двух каталогах, просто указываем из через пробел:
Поиск скрытых файлов
В Linuxе, как и в Виндовс, существуют скрытые файлы, которые при использовании команды find без специального символа показываться не будут. Этот символ – «тильда», а директива будет иметь следующий вид:
Поиск файлов в Linux по разрешениям
Иногда возникает потребность фильтрации каталога по определённой маске прав. Например, если нам нужно найти файлы с атрибутом 0661, используем команду:
Задача фильтрации файлов с атрибутом «только для чтения» решается так:
А вот как будет выглядеть поиск исполняемых файлов в каталоге etc:
Поиск файлов по группах/пользователях
Администратору часто приходится сталкиваться с задачей поиска файлов, являющихся собственностью конкретного пользователя и/или группы. Поиск по юзеру:
Для групп пользователей используется другой параметр:
Поиск по дате последней модификации
Видимый формат даты файла в ОС Linux как раз и относится к дате его модификации (такой же принцип используется и в Windows). Для формирования списка по дате применяется опция mtime. Допустим, нам нужно отыскать файлы, изменённые два месяца назад:

В числе атрибутов файла есть и дата его последнего открытия (без внесения изменений). Такие файлы выводятся следующей командой:
Можно также задавать промежуток времени. Для поиска файлов, модифицированных в промежутке от четырёх до двух месяцев назад, используем директиву:
А вот как найти свежеизменённые файлы (двухчасовой давности):
Поиск файлов по размеру
Подозреваете, что кто-то использует диск для размещения фильмов? Ищем файлы размером 1.4 ГБ:
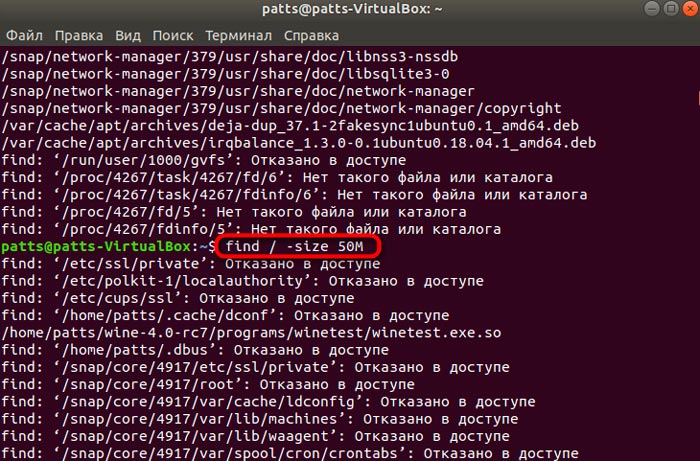
Или используем диапазон:
Поиск пустых файлов/каталогов
Да, не удивляйтесь. Задача наведения порядка на носителе характерна не только для ОС Android. В Linux она решается с помощью такой директивы:
Пример действий с найденными файлами
В Linux команда find рекурсивно может выполнять определённые действия с теми файлами, поиск которых вы ведёте. Для выполнения файловых команд нужно использовать параметр exec. Так, директива для показа информации обо всех файлах с использованием команды ls будет выглядеть так:
А вот как просто можно удалить временные файлы с заданной маской в директории /home/temp:
Безусловно, для новичка использование для поиска командной строки с огромным числом опций покажется несколько вычурным способом, но в Linux это в порядке вещей. А как бы вы решали описанные здесь задачи в Windows? То-то же. В этом аспекте Linux явно впереди.
Как найти все файлы, содержащие определенный текст в Linux?
Я пытаюсь найти способ сканировать всю систему Linux на наличие всех файлов, содержащих определенную строку текста. Просто чтобы уточнить, я ищу текст в файле, а не в имени файла.
Когда я искал, как это сделать, я дважды сталкивался с этим решением:
Тем не менее, это не работает. Кажется, для отображения каждого файла в системе.
Это близко к правильному способу сделать это? Если нет, то как я должен? Эта возможность находить текстовые строки в файлах была бы чрезвычайно полезна для некоторых программных проектов, которыми я занимаюсь.
Это очень хорошо работает для меня, чтобы достичь почти такой же цели, как ваша.
В вашем корневом каталоге.
ОБНОВИТЬ
Ты можешь использовать:
Это напечатает строки в файлах, где появляется текст, но не напечатает имя файла.
Вы можете использовать это:
Список имен файлов, содержащих данный текст
пример
Допустим, вы ищете файлы, содержащие определенный текст «Лицензия Apache» внутри вашего каталога. Он будет отображать результаты, несколько похожие на приведенные ниже (вывод будет отличаться в зависимости от содержимого каталога).
Удалить регистр чувствительности
Надеюсь, это поможет вам.
grep ( GNU или BSD )
Вы можете использовать grep инструмент для рекурсивного поиска в текущей папке, например:
Вы также можете использовать синтаксис globbing для поиска в определенных файлах, таких как:
Если вы ошиблись в том, что ваш аргумент слишком длинный, попробуйте сузить область поиска или используйте find вместо этого такой синтаксис, как:
ripgrep
Если вы работаете над большими проектами или большими файлами, вы должны использовать ripgrep вместо этого, например:
Вы можете использовать общие параметры, такие как:
Как мне найти в Linux все файлы, содержащие определенный текст?
Я пытаюсь найти способ просканировать всю мою систему Linux на предмет всех файлов, содержащих определенную строку текста. Чтобы уточнить, я ищу текст внутри файла, а не в имени файла.
Когда я искал, как это сделать, я дважды наткнулся на это решение:
Однако это не работает. Кажется, отображает каждый файл в системе.
Это близко к правильному способу сделать это? Если нет, то как мне? Эта способность находить текстовые строки в файлах была бы чрезвычайно полезна для некоторых программных проектов, над которыми я работаю.
29 ответов
Это очень хорошо работает для меня, достигая почти той же цели, что и ваша.
Ты можешь использовать:
r означает рекурсивный, поэтому поиск выполняется по указанному пути, а также в его подкаталогах. Это сообщит вам имя файла, а также распечатает строку в файле, где эта строка появляется.
Это напечатает строки в файлах, где появляется текст, но не напечатает имя файла.
Вы можете использовать подтверждение. Это похоже на grep для исходного кода. С его помощью вы можете сканировать всю файловую систему.
В вашем корневом каталоге.
Вы также можете использовать регулярные выражения, указать тип файла и т. Д.
ОБНОВЛЕНИЕ
Вы можете использовать команду ниже, так как вам не нужно имя файла, но вы хотите искать во всех файлах. Вот я захватываю форму «ТЕКСТ» Все файлы журнала, проверяя, что имя файла не печатается.
Приведенная ниже команда отлично подойдет для этого подхода:
Все предыдущие ответы предполагают использование grep и find. Но есть другой способ: использовать Midnight Commander.
Чтобы найти строку и вывести только эту строку со строкой поиска:
Чтобы отобразить имя файла, содержащего строку поиска:
Это сообщит, сколько копий вашего шаблона находится в каждом из файлов в текущем каталоге.
Если вас не волнует регистр текста, который нужно найти, используйте:
Я написал сценарий Python, который делает нечто подобное. Вот как следует использовать этот скрипт.
И вуаля, он генерирует путь к совпадающим файлам и номер строки, в которой было найдено совпадение. Если найдено более одного совпадения, то к имени файла будет добавлен номер каждой строки.
Простой find может пригодиться. укажите псевдоним в вашем файле
Запустите новый терминал и выдайте:
Для домашней папки используйте:
Для текущей папки используйте:
Я очарован тем, насколько просто grep делает это с помощью ‘rl’:
Краткое объяснение опций:
Объяснение из комментариев
Вот несколько списков команд, которые можно использовать для поиска файла.
Это дает вам возможность find находить файлы.
Он работает в Linux, Mac и Windows и был написан на Hacker News пару месяцев назад. (здесь есть ссылка на блог Эндрю Галланта, в котором есть ссылка на GitHub):
grep можно использовать, даже если мы не ищем строку.
Распечатает путь ко всем текстовым файлам, то есть содержащим только печатные символы.
Используйте pwd для поиска из любого каталога, в котором вы находитесь, рекурсивно вниз
Будет делать то же самое, что и выше!
Как мне найти в Linux все файлы, содержащие определенный текст? (. )
Я дважды сталкивался с этим решением:
Более быстрые и простые альтернативы
Он тесно работает с Git и другими VCS. Таким образом, вы ничего не получите в .git или другом каталоге.
Вы можете просто использовать
И он сделает эту задачу за вас!
Если ваш grep не поддерживает рекурсивный поиск, вы можете комбинировать find с xargs :
Это выведет имя файла и содержимое совпадающей строки, например.
Необязательные флаги, которые вы можете добавить к grep :
Список имен файлов, содержащих заданный текст
Примере
Допустим, вы ищете файлы, содержащие определенный текст «Лицензия Apache» внутри вашего каталога. Он будет отображать результаты, несколько похожие на показанные ниже (вывод будет отличаться в зависимости от содержимого вашего каталога).



